Course introduction
Overview
Teaching: 60 min
Exercises: 0 minObjectives
Understand course scope and evaluation criteria
Start and plan an effective lab book
login into Draco
Viromics
Metagenomics of viruses, often referred to as Viromics, is the study of viral communities in a sample or environment through the direct sequencing and analysis of their genetic material. This avoids the need to isolate or culture the viruses, preventing the bias associated with isolation, and allowing the complete viral community to be analyzed. This allows for the identification and characterization of both known and novel viruses within a given ecosystem. In this module, you will learn how to analyse viromics data with computational approaches.
Data
We will be using viromics sequencing data from Natia Geliashvili, a PhD student in the VEO Group. This data was generated by sequencing a phages passed through a 0.22um filter. These phages are part of a sediment/river microbial community, into which a target phage and its host were added. The sequencing was done on a Oxford Nanopore Technologies Flow Cell (long read sequencing).
Theory
The theoretical parts of the course are covered in the mornings. This includes reading relevant papers, watching video lectures, and discussion of the concepts and tools. Please write down any questions and discussion points about the theory in your Lab Notebook (see below).
Hands-on
The practical parts of the course are covered in the afternoons. You will use different bioinformatics tools, compare and interpret the results, and make conclusions about the sampled viruses. We will be available to help and guide you during this time. Please document how you performed the analyses, and write down any questions and discussion points in your Lab Notebook (see below). Solutions for each step are provided. If necessary, you can use them to move to the next steps.
Presentation
You will give a final presentation on Friday 12 September. This is where you can show off your understanding of the material and share what interesting techniques you came up with.
Final evaluation
Your final grade is based on an evaluation of three factors.
- Your professional performance (active participation, asking questions, helping others): 30%
- Your Lab Notebook (approach to address hands-on questions/exercises, tidiness/reproducibility, notes/questions/discussion points): 30%
- The presentation of your final project: 40%
Lab Notebook
Documenting your work is crucial in Computational Biology/Bioinformatics. This way you can make sure your work is reproducible, document your commands to later find back what you did, prepare a first draft of text for other documents (e.g. a Methods section in a report or paper), and collect information which you can send to colleagues. Make sure that it is tidy, commented, and clearly written, so that others can easily understand it, including your future self.
You are required to write a Lab Notebook for this module, which will count as part of your evaluation.
READ THIS FOR NOTES ON YOUR LAB BOOK
Access to Draco
Draco is a high-performance cluster created and maintained by the Universitätsrechenzentrum. It is available for members of Thuringian Universities. To log in, you can use ssh (replace <fsuid> by your FSU login):
ssh <fsuid>@login1.draco.uni-jena.de
Terminal or ssh client
More details on access to Draco
Submitting jobs on Draco
When you login to Draco, you are on the “login node” and this is not the best place to run any programs or heavier scripts. You MUST be on a “compute node” to run scripts and programs
You can either request for resources from a compute node and run programs interactively or submit a job to the job scheduler, which then sends it to a compute node to complete.
See here for what slurm architecture looks like
You can either request resources from a node for an “interactive” shell or you can submit via sbatch
To get resources - see here
To submit a job, you have to make a script my_slurm_script.sh and then submit it as sbatch my_slurm_script.sh . Detailed information on creating these scripts, including descriptions can be found in the “extras” here
Key Points
In this course, you will analyze viral sequence data
You need to keep a lab notebook
You need to be able to access the HPC Draco
Introduction to viromics
Overview
Teaching: 60 min
Exercises: 60 minObjectives
Summarize metagenomics and viromics
Understand what are bacteriophages and how they fit into microbial communities
Compare and contrast microbial and viral diversity
Video on viral metagenomics
Below is a lecture video introducing the concepts of metagenomics, microbial dark matter, and viromics. The case study covered in the video is about crAssphage, a type of bacteriophage that was first found using bioinformatics, by reanalyzing viromics data from the human gut by using the cross-assembly approach. The prevalence and implications of crAssphage are also discussed.
Exercise
Watch the lecture below and write down at least 3 questions and/or discussion points about it.
- Click on the image to see lecture video “Viral metagenomics: predicting phage-microbe interactions in the gut” by Prof Bas E. Dutilh (34 minutes):

Additional reading: Virus Bioinformatics (Pappas et al. 2021)
Exercise - mindmap
Create a mindmap summarizing the following points from the video. A mindmap is a brainstorming graphic. You can get creative using PowerPoint or draw it on paper, take a picture, and upload it into your Lab Notebook.
- What is metagenomics?
- What is viromics?
- What are bacteriophages and how prevalent and abundant are they?
- What are the roles of phages in microbial communities?
- more general, how do they influence the ecology and the environment
- Explain at least three ways that phages can have an impact on bacteria.
- More specifically, how do they influence their host (lytic/ temperate, HGT etc)
- Name at least three differences between the evolution of viral and cellular organisms?
Key Points
Viromics is the study of viruses, and in our case bacteriophages, using next-generation sequencing technologies
Bacteriophages are diverse and ubiquitous across all biomes
Bacteriophages have large implications on their environment including the human gut
Getting to know your files
Overview
Teaching: 120 min
Exercises: 0 minObjectives
Interpret different file formats used in bioinformatics
Utilize bash commands to look into sequence data
Get a basic understanding of what sequence data looks like
Work with sequence data in Python or R to create basic plots
Navigating your filesystem space
First, let’s copy the sequence data to your own home folders.
Exercise - get your sequence data
Once you are on Draco, you will start in your home directory. From there, copy over a script from
/vast/groups/VEO/shared_data/Viromics2025_workspace/setup_workspace.sbatchlocation to your home directory and run it. This script will build the scaffold for all our computational work.# go to home cd ~ # copy over the sbatch cp /vast/groups/VEO/shared_data/Viromics2025_workspace/setup_workspace.sbatch ./ # run the script sbatch setup_workspace.sbatch This script will drop you in the ./Viromics2025_workspace directory - this is where you live from now on.
Exercise - check out your files
- Take a look at the file structure and files. We have given you a subset of viromics data
./data/sequences. Some helpful commands might be: Hint: for gzipped files - you need to zcat them first. e.g.zcat file.fastq.gz | head -10# list ls ll # path to working directory pwd # print first 10 lines zcat file.fastq.gz | head -10 # print last 10 lines zcat file.fastq.gz | tail -10 # open file on terminal (press 'q' to exit less) less more # count number of lines wc -l file.txt # search for "@" inside file grep "@" file.fastq # or gzipped files zgrep "@" file.fastq.gz | head -10 # count number of sequence headers in a fasta file grep -c ">" file.fasta zgrep -c ">" file.fasta.gz
See more useful commands and one-liners here
For creating new directories - please ensure to name your directories with a number and a meaningful header. An example is here
Understanding bioinformatics file formats
It is always a good idea to check the contents of your data files and make regular “sanity checks” to see if you understand everything. The first video covers different file formats commonly used in bioinformatics. Namely, FASTA, FASTQ, BAM, SAM, VCF, BCF, GFF, GTF and BED files (9 minutes).

The second video covers different types of sequence files, including fasta and fastq, phred scores, files containing metadata (tsv files) and compressed files (11 minutes).
Exercise
- What information is contained in sequencing files?
a) Choose 3 file formats and describe them- Choose the virome.fastq.gz file in your data/sequences/ folder
a) How many lines does this file have?
b) How many sequences are present in the file?- Print the first 5 lines and the last 5 lines in the terminal.
Hint: for gzipped files - you need to zcat them first. e.g.zcat file.fastq.gz | head -10
You don’t need to print this output into your lab-book
zcat virome.fastq.gz | cut -b -100 | head -10- to print the first 100 characters of the first 10 lines
a) What differences do you observe between these lines?
Key Points
Sequence data and information about genes and genomes can come in many different formats
The most common file formats are fasta (nucl. and amino acid), fastq, sam and bam, genbank, gff and tsv files
Sequencing Quality Control
Overview
Teaching: 180 min
Exercises: 0 minObjectives
Understand the value of sequencing quality control
Discuss how low quality reads affect genomic analysis
Perform quality check on long-read data by creating plots
Interpret quality check results
Perform quality control on reads
![]()
Every step of a metagenomics/viromics analysis pipeline needs quality control and sanity checks.
- What data am I working with?
- What is the quality of the data or analysis?
- Are my results what I expected them to be? Why?/Why not?
Here, we will assess the quality of DNA sequencing.
Sequencing quality control can include:
- Removing barcodes (i.e. oligonucleotides that were artificially added to identify sequences from a particular sample)
- Removing sequencing adapters (i.e. oligonucleotides that were artificially added to facilitate the sequencing process)
- Removing low-quality nucleotides (sequencing quality often drops towards the end of the reads)
- Filtering out reads based on quality scores (some reads are derived from faulty clusters or pores, and are best ignored)
To prepare your data, we used Nanopore basecaller Dorado to do the basecalling and demultiplexing. This step also trims any adapters, primers and barcodes from the reads.
Exercise
Discuss with your classmates and TAs:
- Why do we need quality control?
- What are some metrics for assessing sequencing quality?
- What are the potential impacts of not performing quality control on your reads?
Assessing Sequencing Quality
We will use NanoPlot to assess the quality of our reads. NanoPlot is designed for long reads and uses information in the sequence files to evaluate the quality of our reads.
Exercise
Run NanoPlot on your reads
- Assess the sequencing quality for each sample using default parameters
- Use fastq files and summary.txt located
./data/sequences/to generate diff types of quality plots (see the NanoPlot github)- Play around with the parameters such as colours and types of plots to generate
# to run nanoplot - you will need to source and activate the following conda environment: source /vast/groups/VEO/tools/anaconda3/etc/profile.d/conda.sh && conda activate nanoplot_v1.41.3 NanoPlot -t ? --plots ? --color ? --fastq barcode1.fastq.gz -o output_dir/barcode1
Resources
Information about Nanopore sequencing quality and Phred scores
How to write a for-loop to loop through your files
sbatch script for NanoPlot
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=10 #SBATCH --partition=short,standard #SBATCH --mem=5G #SBATCH --time=2:00:00 #SBATCH --job-name=sequencing_QC #SBATCH --output=10_nanoplot/nanoplot.slurm.out.%j #SBATCH --error=10_nanoplot/nanoplot.slurm.err.%j # First, we check the quality of the reads using nanoplot # activate the conda environment containing nanoplot source /vast/groups/VEO/tools/anaconda3/etc/profile.d/conda.sh && conda activate nanoplot_v1.41.3 datadir=../data/sequences outdir=./10_nanoplot # Run nanoplot on 3 fastq files in a for loop # -t : threads (cpus) # --plots : types of plots to produce, see gallery: https://gigabaseorgigabyte.wordpress.com/2017/06/01/example-gallery-of-nanoplot/ # --N50 : draw the N50 vertical line on the plots # --color : color for the plots # -o : output directory # to see other options for colors and prefilters, run : NanoPlot -h for fn in $datadir/*.fastq.gz do base_f=$(basename $fn .fastq.gz) # select just the first part of the name NanoPlot -t 10 --plots dot --N50 --color slateblue --fastq $fn -o $outdir/${base_f}/ done
This is an example of a plot you might get from NanoPlot. It is important to look at such a plot to estimate how much data will be lost when you filter by read quality or length.
- The top plot shows frequency of read lengths
- The large main plot shows how the read quality changes by read length
- The right plot shows the frequency of read qualities
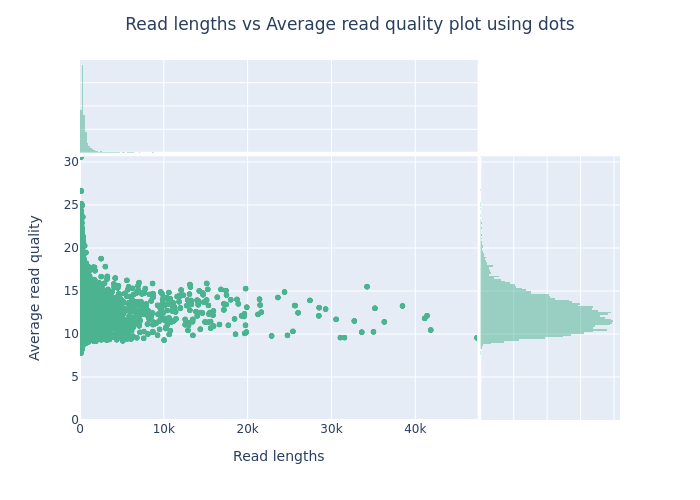
Exercise
- How does the sequencing quality of your virome compare with the above example image? Specify your answer with metrics from the NanoPlot results.
- Do we need to remove any reads from our data? Why (not)?
- What does Q12 mean? How much data will be lost from each sample if we filter at Q12? (Hint: check the Nanoplot outputs)
Filtering Reads
Many phages naturally have low-complexity regions in their genomes (e.g. ACACACACAC). Nanopore sequencing errors are biased towards low-complexity regions, either by falsely generating them or by exacerbating them. This can create artefacts in the assembled viral genome sequences. High-quality reads can significantly improve assemblies, particularly for error-prone long reads.
Exercise - filter your reads
We will use Chopper to filter our reads based on quality scores and length. In our case, a lot of reads are high quality, therefore to reduce the amount of data we process downstreamm, we will use a phred score threshold of 24. Build an sbatch script for chopper based on the following basic usage example. Use the following filtering criteria:
- minimum quality 24
- minimum length 1000 bp
- maximum length 40000 bp
# activate the conda environment source /vast/groups/VEO/tools/anaconda3/etc/profile.d/conda.sh && conda activate chopper_v0.5.0 # base usage for filtering with minimum quality 24 gunzip -c reads.fastq.gz | chopper -q 24| gzip > filtered_reads.fastq.gz # check the help for the other options chopper -h
Chopper sbatch script
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=10 #SBATCH --partition=short,standard #SBATCH --mem=1G #SBATCH --time=2:00:00 #SBATCH --job-name=sequencing_QC #SBATCH --output=20_chopper/chopper.slurm.out.%j #SBATCH --error=20_chopper/chopper.slurm.err.%j # activate the conda environment containing chopper source /vast/groups/VEO/tools/anaconda3/etc/profile.d/conda.sh && conda activate chopper_v0.5.0 datadir="../data/sequences" outdir="20_chopper" # gunzip : unzip the reads # -q : minimum read quality to keep # -l : minimum read length to keep # gzip: rezip the filtered reads for fn in ../data/sequences/*.fastq.gz do base_f=$(basename $fn .fastq.gz) # select just the first part of the name gunzip -c $fn | chopper -q 24 -l 1000 --maxlength 40000 | gzip -2 > $outdir/${base_f}_filtered_reads.fastq.gz done
Exercise
- How many reads do you have left after filtering? What percentage of the original reads were filtered?
- What is the average quality before and after filtering?
- Optional: Run Nanoplot again to show the difference in the read statistics
GC Content
GC Content ((sum of all G’s + C’s) / (sum of all T’s + A’s)) is another interesting metric to evaluate your sequencing data. There’s no “wrong” GC content, rather this measure tells us something about the nucleic acid diversity our metagenomes/viromes. GC content is generally consistent along the length of a genome, as the GC content of sequencing reads from a single genome follows a bell curve. Regions with outlier values often represent non-self regions, for example a horizontally transferred gene, an inserted prophage, or a mobile genetic element. GC content is generally consistent for genomes of similar strains.
Below are three GC plots - Our virome, another random virome + a single E. coli phage T4 phage genome. Please use this plot to answer the following questions.
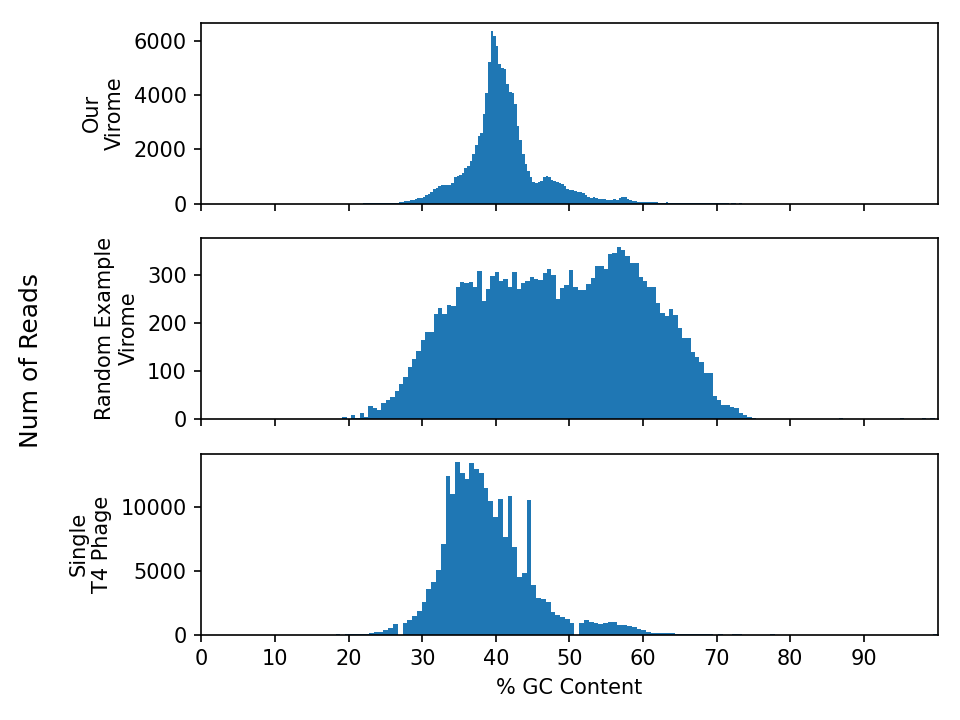
Exercise - GC content plots
Interpret the distributions:
- Are these histograms what you expected? why/why not?
- How would the GC content of a metagenome differ from these viromes?
- Describe the difference in GC content between the viromes and E. coli phage T4.
- For example: What interpretations can you make about the samples based on these plots?
Below is the python script used to make these plots for your reference and future use.
python script to make GC_content plots
To install the libraries
source ./py3env/bin/activate pip install biopython, pandas, numpy, matplotlib#! usr/bin/python3 # import libraries into your script from Bio.SeqUtils import gc_fraction from Bio import SeqIO import pandas as pd import numpy as np import gzip, sys import matplotlib.pyplot as plt file1=sys.argv[1] file2=sys.argv[2] T4_path=sys.argv[3] # read in fastq.gz files gc_62={} with gzip.open(file1, 'rt') as f: for record in SeqIO.parse(f, "fastq"): gc_62[record.id]=gc_fraction(record.seq)*100 print("file1... done") gc_63={} with gzip.open(file2, 'rt') as f: for record in SeqIO.parse(f, "fastq"): gc_63[record.id]=gc_fraction(record.seq)*100 print("file2... done") gc_T4={} with gzip.open(T4_path, 'rt') as f: for record in SeqIO.parse(f, "fastq"): gc_T4[record.id]=gc_fraction(record.seq)*100 #print(gc_fraction(record.seq)*100) print("gc_T4... done") # convert to a pandas dataframe # For your samples df_62 = pd.DataFrame([gc_62]) df_62 = df_62.T df_63 = pd.DataFrame([gc_63]) df_63 = df_63.T # For T4 phage df_T4 = pd.DataFrame([gc_T4]) df_T4 = df_T4.T # make a plotting function def make_plot(axs): # We can set the number of bins with the *bins* keyword argument. n_bins = 150 ax1 = axs[0] ax1.hist(df_62, bins=n_bins) ax1.set_ylabel('Our\nVirome', fontsize=10) ax1.set_xlim(0, 100) ax1.set_xticks(np.arange(0, 100, step=10)) ax2 = axs[1] ax2.hist(df_63, bins=n_bins) ax2.set_ylabel('Random Example\nVirome',fontsize=10) ax4 = axs[2] ax4.hist(df_T4, bins=n_bins) ax4.set_ylabel('Single\nT4 Phage',fontsize=10) ax4.set_xlabel('% GC Content', fontsize=10) # Plot: fig, axs = plt.subplots(3,1, sharex=True, tight_layout=True) make_plot(axs) fig.supylabel('Num of Reads') plt.show() # save your plot fig.savefig('GC_Content.png', dpi=150)
Key Points
Sequencing quality control is an important first evaluation of our data
NanoPlot can be used to evaluate read quality of long reads
Chopper can be used to filter reads based on quality and/or length
The GC content profile of a metagenome or virome is composed of a mix of bell curves
Assembly lecture
Overview
Teaching: 120 min
Exercises: 60 minObjectives
Watch the lecture videos and read about assembly algorithms
![]()
Sequence assembly is the reconstruction of long contiguous sequences (called contigs or scaffolds, see video below) from short sequencing reads. Before 2014, a common approach in metagenomics was to compare the short sequencing reads to the genomes of known organisms in the database (and some studies today still take this approach). However, this only works if the organisms in the database are closely related to the ones in the metagenomic sample. Recall that most of the sequences in a metavirome are unknown (“viral dark matter”), meaning that they yield no matches when compared to the reference database. Because of this, we need database-independent approaches to reconstruct new viral sequences. As sequencing technology and bioinformatic tools improved, sequence assembly enabled the recovery of longer sequences from metagenomic data. Having a longer sequence means having more information to classify it, so using metagenome assembly helps to characterize complex communities.
Video on sequence assembly
Watch the lecture video “Assembly strategies for genomics and metagenomics”. It will introduce reference-guided and de-novo assembly of genomic and metagenomic sequences (56 minutes):
Discussion
Watch the lecture video below and write down at least 3 questions and/or discussion points about it.
- Click on the image to see lecture video “Assembly strategies for genomics and metagenomics” by Prof Bas E. Dutilh (56 minutes):
Questions
- Would you use DBG (De-Bruijn Graph) or OLC (Overlap-Layout-Consensus) to assemble a dataset consisting of one billion short sequencing reads?
- What are the strengths and weaknesses of reference-guided assembly and de novo assembly?
- Would you use reference-guided or de novo assembly to assemble the genome of a model organism to discover mutations that occurred during an evolutionary experiment?
- Would you use reference-guided or de novo assembly to determine the genome sequence of an unknown organism?
- Why does metagenome assembly generally yield shorter contigs than genome assembly?
Additional reading: Computational Biology: Genomes, Networks, Evolution MIT course 6.047/6.878 (Prof. Manolis Kellis). This book is part of a course on Computational Biology and contains several topics that are relevant for Bioinformatics.
Read and summarize
Read the following sections and summarize shortly (less than half a page per section) their key points in your lab book:
- “5.2 Genome Assembly I: Overlap-Layout-Consensus Approach” and “5.3 Genome Assembly II: String graph methods” (pages 93 to 102).
Key Points
Sequence assembly can be used to assemble genomes from reads
Metagenome assembly generally yields shorter contigs than genome assembly
Assembly of a metavirome
Overview
Teaching: 30 min
Exercises: 210 minObjectives
Assemble a metavirome from reads
In this lesson, you will assemble the metavirome using the tool Flye introduced in this article. To then get a first idea about the diversity of the viral sequences contained in it, we will use vclust to group sequences together based on their similarity. Flye was designed to work well with noisy long reads and for metagenomic samples. Since you work on Draco, everything even slightly computationally expensive will be run through slurm. Please organize all the following steps in one or more sbatch scripts, as you learned yesterday. Since every tool needs different resources, it is recommended to have a single script per tool. All code snippets presented here assume that you put them in an adequate sbatch script. The necessary resources are mentioned in the comments or descriptions.
Assembly of a metavirome
There are multiple ways in which you can assemble reads from multiple samples as we have in our experimental data. We can just combine all data we have (replicates and conditions), to increase the coverage per virus. This can often be beneficial if the sequencing depth is not deep enough in the individual samples. Alternatively, we can assemble each sample indivudally. This preserves differences between samples which could get lost otherwise. Here, we will focus on a single assembly of a single file.
Exercise - Use flye to assemble one sample
To run a single sample assembly, you can use flye and output the assemblys into the folder 10_results_assembly_flye:
# The assembly can require large amounts of memory and time, depending on the number of reads # and the diversity of the virome we want to study. Since we reduced the number of reads # specifically to get a quick assembly, we can use about 50GB of RAM and 10 cores. flye --nano-hq /path/to/barcode$barcode.fastq.gz --meta --genome-size 30m -t 10Here you can find an overview over the possible parameters.
Flye can be used for single-organism assemblies as well as metagenomic assemblies. Your sequences were generated with the Nanopore MinION platform and filtered to contain only high quality reads. You can pass an estimate of the size of your metagenome to flye, i.e., the combined length of the assembled contigs. It is difficult to accurately predict this if you do not know what’s in your samples (as in our case). How would you very roughly estimate this number by upper and lower bounds?
After you have finalized your sbatch script with the resource assignments and the completed commands, you can run it to submit the assembly as a job to the Draco, our computational cluster. You can check the output of your script in the slurm log files which you can set with the sbatch parameters at the beginning of your script. Check both files. Often, the error output contains more than just errors, and this file is the more informative one.
#SBATCH --output=10_results_assembly_flye/assembly_flye.slurm.%j.out #SBATCH --error=10_results_assembly_flye/assembly_flye.slurm.%j.errFlye creates an assembly in multiple steps. You can read through the Flye log file that you defined with the
#SBATCH --error=parameter. Afterward, you can find a list of all assembled contigs with additional information in the fileassembly_info.txt, located in the Flye output folder.
- What are the longest and shortest contig lengths?
- What is the range of depth (coverage) values?
- How many circular contigs were assembled? Do you think this percentage is high or low?
- How does your guess about the size of the metagenome (above) compare to the actual size?
sbatch script for the assembly
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=32 #SBATCH --partition=short,standard #SBATCH --mem=20G #SBATCH --time=01:00:00 #SBATCH --job-name=assembly_flye #SBATCH --output=10_assembly_flye/assembly_flye.slurm.%j.out #SBATCH --error=10_assembly_flye/assembly_flye.slurm.%j.err # run flye in metagenomic mode for de-novo assembly of viral contigs # First, activate the conda environment which holds the flye installation on draco: # First, activate the conda environment which holds the flye installation on draco: source /vast/groups/VEO/tools/miniconda3_2024/etc/profile.d/conda.sh && conda activate flye_v2.9.2 # set a data directory holding your samples in .fastq.gz format datadir="../1.1_QC/20_chopper" # single assemblies # Run flye on all samples sequentially, save the results in separate folders named like the samples: outdir="10_assembly_flye" flye --nano-hq $datadir/virome_filtered_reads.fastq.gz --meta --genome-size 10m --out-dir $outdir -t 30 conda deactivate
Estimating the sequence diversity in your assembly
Which viruses did we sequence now? Without further analysis, we only have a nucleotide sequence and corresponding abundance estimates from the assembly. In the next days we will go through several steps to characterize the sequences we assembled now in more detail. Now, as a first overview over the diversity of the sequences, we will cluster them at 95% Average Nucleotide Identify (ANI) over 85% of the length of the shorter sequence. These cutoffs are often used to cluster viral genomes at the species rank. This can be done with the tool vClust and results in both, clustering very similar complete viral genomes and grouping genome fragments along with similar and longer sequences.
Exercise - use vClust to find simililar contigs
vClust can also output cluster representatives, which will be the longest sequences within a cluster. We use this mode to get the information we need to to estimate the diversity of the virome we sequenced. You can play with the similarity cutoffs (and metrics) used for clustering to see how they affect the results. vClust needs to align all sequences to each other and can run heavily in parallel. Remember to put this step into a sbatch script again and assign around 30 cores and 20GB of RAM.
# vClust is a python script and can be run by simply calling it on draco # you have to run it with python 3.9 vclust='python3.9 /home/groups/VEO/tools/vclust/v1.0.3/vclust.py' $vclust prefilter -i 10_results_assembly_flye/single_assemblies/assembly.fasta ... $vclust align ... $vclust cluster ...After vClust ran successfully, you can use a Python script to analyze the clusters computed by vClust. To parse a tabular file in the format of CSV or TSV (comma- or tab-separated values), the Python package pandas can be used. If its not in your virtual environment, install it now.
Pandas can be used to analyze the output of vClust. Some interesting aspects of the clusters we can compute from the cluster assignments allone are the number of clusters and how large the clusters are.
import pandas as pd import os from collections import Counter # read the tsv file generated by vClust cluster_df = pd.read_csv('path/to/the/file.tsv', sep='\t') # use python's Counter object to count the "cluster" column in the vClust output table cluster_counter = Counter(cluster_df["cluster"]) # use the counter object to compute how many clusters there are and how large they are ...
Python script for analyzing cluster sizes
import os import pandas as pd from collections import Counter vclust_results_path = './1.2_assembly/20_results_assessment_vclust/' for results_file in ("clusters_tani_90.tsv", "clusters_tani_70.tsv", "clusters_ani_90.tsv"): # read the tsv file generated by vClust cluster_df = pd.read_csv(os.path.join(vclust_results_path, results_file), sep='\t') # use python's Counter object to count the "cluster" column in the vClust output table cluster_counter = Counter(cluster_df["cluster"]) n_clusters = len(cluster_counter) largest_clusters = cluster_counter.most_common(10) # output number of clusters and the sizes of the largest clusters print(results_file) print(f"Number of clusters: {len(clusters}") print("\n".join([f"{mc[0]}: {mc[1]}" for mc in largest_clusters]))
sbatch script for running vclust
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=32 #SBATCH --partition=short,standard #SBATCH --mem=10G #SBATCH --time=01:00:00 #SBATCH --job-name=vclust #SBATCH --output=20_vclust/vclust.slurm.%j.out #SBATCH --error=20_vclust/vclust.slurm.%j.err vclust='python3.9 /home/groups/VEO/tools/vclust/v1.2.7/vclust/vclust.py' indir='10_assembly_flye/' outdir='20_vclust/' $vclust prefilter -i $indir/assembly.fasta -o $outdir/fltr.txt $vclust align -i $indir/assembly.fasta -o $outdir/ani.tsv -t 30 --filter $outdir/fltr.txt $vclust cluster -i $outdir/ani.tsv -o $outdir/clusters_tani_90.tsv --ids $outdir/ani.ids.tsv --metric tani --tani 0.90 --out-repr $vclust cluster -i $outdir/ani.tsv -o $outdir/clusters_tani_70.tsv --ids $outdir/ani.ids.tsv --metric tani --tani 0.70 --out-repr $vclust cluster -i $outdir/ani.tsv -o $outdir/clusters_ani_90.tsv --ids $outdir/ani.ids.tsv --metric ani --ani 0.90 --out-repr source ../py3env/bin/activate python3 ../python_scripts/1.2_vclust_results.py deactivate
Questions - Go through the results of vClust
vClust is a great tool to get a feeling for the diversity within your assemblies (or any kind of set of sequences).
- How many sequence clusters were found in your assembly and how many sequences were grouped in the largest one?
- How do the results depend on the choice of your metric (ANI, TANI, or GANI) and your cutoff values?
Key Points
Flye can be used to assemble long and noisy nanopore reads from metagenomic samples.
Samples can be assembled individually and combined in a cross-assembly
vClust can be used to assess the diversity of sequences in your assembly
Visualizing the assembly
Overview
Teaching: 0 min
Exercises: 60 minObjectives
Understand the topology of the de-Bruijn graph
Understand how the presence of similar species in the sample affects the assembly
Contig length distribution
To get an idea about the quality of your assembly, i.e. the degree of fragmentation and potentially full length complete viral genomes, it is helpful to look at the distribution of the length of the generated contigs. We can discribe this distribution using some numbers derived from it, such as the minimum, maximum or median length and something called N50 or N90. These numbers are computed by concatenating all contings ordered by their length. The length of the contig sitting at 50% (or 90%) of the total length of all contigs combined this way, is called N50 (or N90). The QUAST program (Gurevich et al., 2013) can be used to compute these values and visualize the distribution of the contig lengths. The tool can additionally use a reference sequence to compare the assembly against for assessing its fragmentation. We do not have a reference and will use the basic analysis of Quast.
Exercise - Use Quast to compute the contig length distribution
Use the Quast program to visualize the distribution of the contig lengths. You will need to run it two times, once per assembly, and save the results to different folders (ie.
result_quast/cross_assemblyandresult_quast/single_assemblies). Quast does not need many ressources. Assigning 2 CPUs and 5 GB of RAM for sbatch should be enough.# create a folder for the assessment within todays folder $ mkdir 30_results_assessment_quast # Quast is already installed on the server. Its a python script located here: $ quast='python3 /home/groups/VEO/tools/quast/v5.2.0/quast.py' # run quast $ $quast -o 30_results_assessment_quast/cross_assembly /path/to/your/cross_assembly/assembly.fastaYou can get the results from the file
report.txtor copy the whole results folder to your computer and openreport.htmlin your local browser.
How fragmented is your assembly?
The distribution of contig lengths can already tell you a lot about the assembly. Combined with some prior knowledge about the sample you sequenced, we can use it as an indicator of the quality or completeness of the assembly.
- What would be 2 extreme cases of length distributions? (Something other than no contigs at all :))
- How do the numbers we computed fit into your expectations about the sample you analyzed?
sbatch script for running Quast
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=2 #SBATCH --partition=short,standard,interactive #SBATCH --mem=1G #SBATCH --time=00:30:00 #SBATCH --job-name=quast #SBATCH --output=30_quast/quast.slurm.%j.out #SBATCH --error=30_quast/quast.slurm.%j.err # Set some variables for the quast script on draco and the files to be analysed quast='python3 /home/groups/VEO/tools/quast/v5.2.0/quast.py' assembly='10_assembly_flye/assembly.fasta' outdir='30_quast' # run Quast to visualize the distribution of contig lengths $quast -o $outdir/assembly $assembly
Optional: Paths in the de-Bruijn graph
We will use Bandage, a tool to visualize
the assembly graph. Bandage is difficult to run on a Windows computer. In the
releases section, follow the instructions
to download the most appropriate version, such as Bandage_Ubuntu-x86-64_v0.9.0_AppImage.zip.
To run it, unzip the file and call Bandage from the terminal like this:
# run Bandage
$ ./Bandage_Ubuntu-x86-64_v0.9.0.AppImage
In File > Load_graph, navigate to and load the file assembly_graph.fastg of
the cross-assembly. Then click Draw graph to visualize the graph. Note that
this graph has already been compacted by collapsing nodes that form linear,
unbranching paths into unitigs. Nodes in the graph are called edge_N (confusing name…)
with N being an integer. They often correspond to the final contigs in your assembly.
Bubbles and junctions
Open the file
assembly_info.txtcorresponding to the graph you are looking at. The N in the node names as displayed by Bandage corresponds to the number assigned to continuous paths in the de-Bruijn graph by Flye. The “graph_path” column holds this information for all contigs.
- What does an asterisk * mean?
- What do multiple occurrences of the same number mean?
Pick two components of the visualized de-Bruijn graph and explain their topology and information content.
- Are there bubbles and junctions?
- Can you relate the complexity of the visualized graph to the Flye command line parameters?
Key Points
Bandage can visualize the de-Bruijn graph
JBrowse2 can visualize genomic data like alignments and coverage
Identifying Viral Contigs I
Overview
Teaching: 0 min
Exercises: 300 minObjectives
Understand the concept and structure of benchmarking virus identification tools
Evaluate the benchmarking results presented in the paper by Wu et al
Choose a virus identification tool
![]()
Comparing Virus Identification Tools
In this theoretical part, you will dive into a very important part of microbiome data analysis: how to choose a good tool. Several tools have been developed over the past years for identifying viral sequences. Each tool measures different aspects of the sequence, applies different algorithms to extract and compare the information, and uses different reference databases to distinguish viral from non-viral sequences.
To choose the best one for your project, you should consider the overall performance of the tools (e.g. sensitivity and specificity, but also ask whether the purpose of the tool aligns with your research goal. If a recent tool does the same task as a previously published one, the authors should compare (or benchmark) them in their publication. But benchmarks can be biased, so ideally, bioinformatic tools are benchmarked by independent scientists.
Today, we will study the paper: “Benchmarking bioinformatic virus identification tools using real‐world metagenomic data across biomes” (Wu et al., 2024). Considering the allocated time for this activity, you will probably not be able to read the entire paper. To answer the proposed questions, please focus on Figures 1, 3, and 6 (and associated Methods and Results paragraphs, search online when necessary).
Questions
The authors investigated nine tools, which can be divided into three categories. What categories? Describe the basic approach of each category of tools.
What is meant by the sets of True Positives, False Negatives, False Positives, and True Negatives in Figure 1? Explain what each of these sets can tell us in the benchmark, and explain how they were generated.
In Figure 3 A/B/C, what indicates a good performance? What is the main takeaway from these figures?
Overall, which types of tools perform better? Why do you think that is?
Considering all you have learned from the paper, is there an ideal tool to identify viral sequences? Why (not)?
Optional 1. Explain what is shown in Figure 6. Do you believe it? What value does this analysis add to the benchmarking?
Optional 2. In Figure 3 D/E/F, the terms TPR, FPR, and AUC/ROC are used for evaluation. What are those terms?
Optional 3. For a potential project you could develop in this module, which tool(s) would you use? Why?
Key Points
Different approaches can be used in a virus identification tool, such as reference-based and machine learning
Benchmark is a comparison between tools and should offer concrete evidence of performance, such as number of TP, FN, FP and TN
When choosing a tool, you should consider the priorities of the project. E. g. you need to identify as many viruses as possible and FP are not critical, so a tool with high recall is ideal
Identifying viral contigs II
Overview
Teaching: 0 min
Exercises: 180 minObjectives
Identify phage contigs in an assembled virome
Interpret Jaeger’s output
Assess assembly completeness
Select medium-complete and low-contaminated contigs
Select viral contigs for further analysis
In this section, we will identify viral sequences among our assembled contigs. This morning, you studied how Wu et al. benchmarked nine bioinformatic virus identification tools. As many of those tools are quite slow, we will use a different tool that was developed by the VEO-MGX Groups: Jaeger. Jaeger was developed after the Wu et al. benchmarking study, so we will test how well it performs ourselves by running it on the virome contig dataset.
Document your activities and answer the questions below in your lab book. Do not forget to cite all relevant sources in your work.
Identify viral contigs
We will start to identify viral contigs with Jaeger.
Challenge
- Elaborate on why is it important to use tools like Jaeger on viromes?
Note that Jaeger should require a bit more than 1 GB for the sbatch job, so make sure to allocate at least 2 GB of memory. Allocate 10 threads. Jaeger can run on CPU nodes, but it’s speed is optimal when run on GPU nodes. In the parameter --partition of the sbatch script, you could add gpu,short to allocate the job to a either a GPU, or a (short or standard times) CPU node. Jaeger should take a few seconds to run.
Exercise
Run Jaeger using the assembly as input:
- Read and interpret the output following Jaeger’s webpage
module load nvidia/cuda/12.1.0 source /vast/groups/VEO/tools/miniconda3_2024/etc/profile.d/conda.sh conda activate jaeger_dev python3 /home/groups/VEO/tools/jaeger/v1.1.30a0/Jaeger/bin/jaeger run -i <file> -o <output_file>Inspect the output files after running Jaeger, and answer the questions below.
head <output>
sbatch script for jaeger
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=10 #SBATCH --partition=gpu,short,standard #SBATCH --mem=3G #SBATCH --time=2:00:00 #SBATCH --job-name=jaeger #SBATCH --output=10_jaeger/jaeger.slurm.%j.out #SBATCH --error=10_jaeger/jaeger.slurm.%j.err #The most updated version of Jaeger is from 20240806 module load nvidia/cuda/12.1.0 source /vast/groups/VEO/tools/miniconda3_2024/etc/profile.d/conda.sh conda activate jaeger_dev assembly='../1.2_assembly/10_assembly_flye/assembly.fasta' outdir='10_jaeger' jaeger='python3 /home/groups/VEO/tools/jaeger/v1.1.30a0/Jaeger/bin/jaeger run' $jaeger -i $assembly -o $outdir
Questions
- Do the results corroborate your expectations?
- Why are not all contigs in the virome identified as viral contigs?
Take the longest contig from the dataset and BLAST it using blastn. What are the top hits? Are they expected?
- How many viral contigs are there in the virome?
bash command for getting the number of phage contigs
cut -f 3 <file> | sort | uniq -c
To get a command to get the sequence of a contigID, you could go to “Extract contig fasta” of the tutorial of Gene Calling and Functional Annotation II.
Estimating genome completeness
There are tools to assess the completeness of bacterial and viral genome sequences. For viruses we use CheckV. The tool identifies genes on the query sequence and compares them to a database of viral and bacterial marker genes. Each taxonomic group of bacteria or phages, e.g. a species or a family, has certain marker genes on its genome. So based on the number and types of marker genes, CheckV can figure out to which taxon a query contig belongs to and estimates how much of the genome it represents (estimated completeness). Note that, we will improve the taxonomic annotation in the “Viral Taxonomy and Phylogeny” section next week. CheckV also checks for unexpected marker genes on the sequence (estimated contamination), and whether part of a phage contig likely represents bacterial sequences, in which case the fragment could be part of a host genome with an integrated prophage.
Allocate 20 threads and at least 20 GB memory for the sbatch job. It should take ~1 minute to run.
# create a folder for the assessment (or let sbatch create it when you assign the output and error log files)
$ mkdir 20_results_assessment_checkv
# activate the conda environment containing the checkv installation
$ source /vast/groups/VEO/tools/anaconda3/etc/profile.d/conda.sh && conda activate checkv_v1.0.1
# run checkV on both assemblies
$ checkv end_to_end ...
sbatch script for running checkV
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=20 #SBATCH --partition=short,standard #SBATCH --mem=20G #SBATCH --time=02:30:00 #SBATCH --job-name=checkv #SBATCH --output=20_checkv/checkv.slurm.%j.out #SBATCH --error=20_checkv/checkv.slurm.%j.err # run CheckV to assess the completeness of single-contig virus genomes. # First, activate the conda environment which holds the CheckV installation on draco: source /vast/groups/VEO/tools/anaconda3/etc/profile.d/conda.sh && conda activate checkv_v1.0.1 # CheckV parameters (https://bitbucket.org/berkeleylab/checkv/src/master/#markdown-header-running-checkv) # checkv end-to-end runs the CheckV pipeline from end to end :). It expects an input fasta file # with the assembly and an output path. # -t: threads # assigning variables for readability database='/veodata/03/databases/checkv/v1.5' outdir='20_checkv' assembly='../1.2_assembly/10_assembly_flye/assembly.fasta' checkv end_to_end -t 20 -d $database $assembly $outdir
Go through the CheckV results
CheckV produces many output files, and also saves files for the intermediate steps of the tools that are used to find viral marker genes (diamond and hmmsearch). A summary of all results can be found in the file
quality_summary.tsv. Open the file and familiarize yourself with the information presented in the table. On CheckV’s website, you can find information about the output in the sections “How it works” and “Output files”.
- How are completeness and length related? (qualitative answer, name examples)
- What are possible reasons for contigs with low completeness to appear in the assembly?
Filter contigs
Exercise - select high-quality phage contigs
Use Jaeger’s predictions (‘phage’ or ‘non-phage’) and CheckV’s estimates of completeness and contamination to separate phage from non-phage contigs and reduce our assembly to high-quality contigs of high completeness. If you are an experienced programmer and have enough time, write (a) script(s) for that. If not, use the solutions below directly. For the solutions below, we used file
assembly_default_jaeger.tsv, however, you could also useassembly_default_phages_jaeger.tsv, which already filters out non-phage contigs. The results of CheckV are located in the filequality_summary.tsvlocated in CheckV’s output folder. As a rule of thumb, you could keep all contigs with completeness >50% and contamination <5%. These values could be changed depending on the data and on the project. Note that filtering for low completeness can remove some conserved regions. Allocate 2 threads and 1GB memory for this job. It should take only a few seconds to run.To read the tabular files, you can use python’s pandas package. If you didn’t do this yesterday, install it in your virtual environment now.
Then, you can load a .tsv file and select content from it like this:
import pandas as pd # the .tsv format separates cells by a tab ('\t') jaeger_df = pd.read_csv(jaeger_results_path, sep='\t') # create a python set of contig names that stick to the if-statement in the loop jaeger_selection = {row['contig_id'] for index, row in jaeger_df.iterrows() if row['prediction'] == 'phage'} # do the same for the checkv results and use set operations to get the contigs selected by both tools joint_selection = jaeger_selection.intersection(checkv_selection) # modify the code from yesterday (rename and filter contigs) to go through the assembly and save contigs in the joint selection ...
python script for selecting viral contigs
import os, sys import pandas as pd from Bio import SeqIO def main(): assembly_path = os.path.abspath(sys.argv[1]) assert assembly_path.endswith(".fasta") jaeger_results_path = os.path.abspath(sys.argv[2]) assert jaeger_results_path.endswith(".tsv") checkv_results_path = os.path.abspath(sys.argv[3]) assert checkv_results_path.endswith(".tsv") out_fasta = os.path.abspath(sys.argv[4]) assert out_fasta.endswith(".fasta") # read the tsv files as pandas dataframes jaeger_df = pd.read_csv(jaeger_results_path, sep='\t') checkv_df = pd.read_csv(checkv_results_path, sep='\t') # collect the sets of contigs which stick to our selection cutoffs jaeger_selection = {row['contig_id'] for index, row in jaeger_df.iterrows() if row['prediction'] == 'phage'} checkv_selection = {row['contig_id'] for index, row in checkv_df.iterrows() if row['completeness'] > 50 and row['contamination'] < 5} # use set operation union to get the contigs in the jaeger set AND in the checkv set joint_selection = jaeger_selection.intersection(checkv_selection) # print some numbers print(f"Number of input contigs: {len(jaeger_df.index)}, selected by jaeger: {len(jaeger_selection)}, selected by checkv: {len(checkv_selection)}, joint selection: {len(joint_selection)}") # define list of records to keep and fill it by comparing the contig id of each record to the joint set of selected contigs out_records = [] with open(assembly_path) as handle: for record in SeqIO.parse(handle, "fasta"): if record.id in joint_selection: out_records.append(record) # write the selected records into a new file with open(out_fasta, "w") as fout: SeqIO.write(out_records, fout, "fasta") if __name__ == "__main__": main()
sbatch script for submitting the python script
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=2 #SBATCH --partition=short #SBATCH --mem=1G #SBATCH --time=00:30:00 #SBATCH --job-name=filter_contigs #SBATCH --output=30_filter_contigs/filter_contigs.slurm.%j.out #SBATCH --error=30_filter_contigs/filter_contigs.slurm.%j.err # activate the python virtual environment with the packages we need source ../py3env/bin/activate # in this sbatch script, its not necessarry to create the directory, # we already told sbatch to create it for the log files. # mkdir -p 30_results_filter_contigs # In this solution, our script takes the assembly and the files # 'complete_contigs_default_jaeger.tsv' from jaeger and # 'quality_summary.tsv' from CheckV as an input. Set them as variables # for readability assembly='../1.2_assembly/10_assembly_flye/assembly.fasta' jaegerresults='10_jaeger/assembly/assembly_default_jaeger.tsv' checkvresults='20_checkv/quality_summary.tsv' outdir='30_filter_contigs' # run our script for filtering contigs based on the output of jaeger # and CheckV as well as the output path. python ../python_scripts/1.3_filter_contigs.py $assembly $jaegerresults $checkvresults $outdir/assembly.fasta # deactivate the environment deactivate
Compare the results
CheckV and Jaeger follow different approaches, and we expect their outputs not to match perfectly. Estimate how different their predictions are.
At the selected cutoffs, how many contigs get chosen by Jaeger, how many by CheckV?
How many Jaeger hits were annotated by CheckV as having high-quality?
To find how many Jaeger hits were annotated by CheckV as high quality:
cut -f1 assembly_default_phages_jaeger.tsv > phage_contigs_jaegar.list grep -w -Ff phage_contigs_jaegar.list 20_results_assessment_checkv/cross_assembly/quality_summary.tsv | grep "High-" | wc -l
Key Points
Filtering contigs by completeness and contamination is crucial to obtain an informative dataset
Tools like Jaeger classify your contigs, enabling you to understand your samples
No wet-lab or dry-lab technique is perfect. Filtering non-viral contigs from your data improves its quality, helping you obtain better results
Gene Calling and Functional Annotation I
Overview
Teaching: 180 min
Exercises: 60 minObjectives
Understand what is gene calling and functional annotation
Investigate the features of phages and how it impacts ORF annotation
Understand what information functional annotation can provide
![]()
Gene Finding
Once we have an assembled genome sequence (or even a contig that represents a fragment of a genome), we want to know what kind of organism the sequence belongs to (taxonomic annotation), what genes it encodes (gene annotation or gene calling), and the functions of those genes (functional annotation). Ideally, gene calling uses a good gene model that is tailored to the organism of study, but to determine the organism we need to know its genes. So it can be an iterative process. In our case, there are pretty good standard gene models available for bacteria and for phages, which we will use.
Phage genomes have specific features that are important to keep in mind. The following lecture by Dr. Robert Edwards explains these, and how they were taken into account when developing a specialized phage gene caller Phanotate.
- Click on the image to see the lecture video “Phage Genomics” by Dr. Rob Edwards (29 minutes):

The video below by Dr Evelien Adriaenssens explains more about phage genome structure and functional annotation
- Click on the image to see the lecture video “Basics of phage genome annotation & classification: getting started” by Dr Evelien Adriaenssens (68 minutes, watch from 12:02 to 30:45):

Exercise
Watch the video lectures for gene finding and functional annotation to answer the questions below:
- What is genome annotation?
- What are ORFs and why are they important in annotating genes?
- Explain the Phanotate algorithm.
- Name at least 3 features of phages should be considered when developing a phage gene annotation tool
Additional Resources
The links of Prodigal and Phanotate might also useful for answering the questions.
As additional material, the video by Dr. Katelyn McNair contains explanations of the algorithm of Phanotate. The topic is similar to the video by Dr. Robert Edwards, but more detailed about the algorithm
Functional Annotation
Once you have ORFs for your phage genomes, you might be curious to what genes they represent. Annotating genes on a genome is called functional annotation and gives insights into the phage lifestyle (lytic or lysogenic), taxonomy, hosts interactions and much more. Therefore, this is probably one of the most biologically informative and interesting steps of the viromics pipeline.
To annotate the phage genomes we will use a tool called Pharokka. Pharokka uses phannotate for the gene calling.
Exercise
The pharokka paper.
Please read the paper for pharokka - from sections 1 - 2.4 to answer the following questions:
- What genomics features are taken into account in the pharokka algorithm?
- How does pharokka assign functional annotations to ORFs using PHROGs?
- What is an HMM?
Additional Resources
The PHROG paper and the PHROGs database might also be useful for you
A caveat to pharokka
As pharokka uses PHROGs to annotate viral genomes, it is limited in the types of auxiliary metabolic genes it can assign. This limitation is set by which genes were previously classified as AMGs and therefore have a PHROG. De novo assignment of AMGs is not possible. AMGs therefore might be better assigned by using a bacterial or a combination viral+bacterial functional annotation tool like DRAM
Key Points
Genome annotation gives meaning to genomic sequences
ORFs can be predicted from start and stop codons in the genomic sequences
Phages have different genomic features than prokaryotes, which influences the design of algorithms
Tools like Phanotate are very useful to process a large amount of contigs. However, no tool is perfect, so a critical interpretation of the results is important
Functional annotation of viral genomes can give clues about viral lifestyle and host interactions
Gene Calling and Functional Annotation II
Overview
Teaching: min
Exercises: 240 minObjectives
Perform gene calling and functional annotation on the viral contigs
Running pharokka
For the functional annotation of our viral contigs, we will be using Pharokka. The “viral contigs” are the contigs we filtered yesterday (i.e. using Jaeger and CheckV)
We first have to load the appropriate conda environment
source /vast/groups/VEO/tools/anaconda3/etc/profile.d/conda.sh
conda activate pharokka_v1.7.1
The base usage for this program follows:
pharokka.py -i <fasta file> -o <output folder> -d <path/to/database_dir> -t <threads>
See the docs for the pharokka parameters
We have to add the following options:
- the pharokka database is here:
/work/groups/VEO/databases/pharokka/v1.7.1/ - To run on viral contigs from a metavirome:
-m - To also use PyHMMER
--meta_hmm - To use Phanotate for the gene prediction:
-g phanotate
Therefore your command should look like this:
pharokka.py -i filtered_assembly.fasta -o output_dir -d path/to/database -t 10 -m --meta_hmm -f -g phanotate
We recommend modifying the following SBATCH resources:
- #SBATCH –cpus-per-task=10
- #SBATCH –partition=short,standard,interactive
- #SBATCH –mem=10G
Exercise
Run pharokka with the appropriate parameters using an sbatch script
sbatch script for pharokka
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=10 #SBATCH --partition=short,standard #SBATCH --mem=20G #SBATCH --time=02:00:00 #SBATCH --job-name=pharokka #SBATCH --output=10_pharokka/pharokka.slurm.%j.out #SBATCH --error=10_pharokka/pharokka.slurm.%j.err source /vast/groups/VEO/tools/anaconda3/etc/profile.d/conda.sh && conda activate pharokka_v1.7.1 database='/veodata/03/databases/pharokka/v1.7.1/' assembly='../1.3_virus_identification/30_filter_contigs/assembly.fasta' outdir='10_pharokka/results' mkdir -p $outdir # extra options to use # -m: run in metavirome mode (each contig is a new virus) # --meta_hmm : also run PyHMMER on the PHROGS (richer annotations with this) # -f: force restart the outputs # -g: gene annotation by phanotate (default for meta mode is prodigal-gv) pharokka.py -i $assembly -o $outdir -d $database -t 10 -m --meta_hmm -f -g phanotate
Plotting functional annotations
Choose a pet contig (or two)
Exercise - extracting contig information
Choose a pet contig. Maybe your favourite contig number… but we recommend choosing one with high completeness and which is ‘annotation-rich’
- perhaps with many annotated genes, a crispr region, mash results (from pharokka) etc.
- Discuss with your classmates so that everybody picks a different virus one. We will continue using this “pet” contig in the future lessons also. a) Write down some information about your contig. e.g. contig length, # of genes, # of annotated genes, gc%, coding density
For the plotting we, we will still use pharokka. Pharokka’s built-in pharokka_plotter.py uses a python library called pyCirclize. You will also use this library later for the visualization homework so stay tuned!
pharokka_plotter.py requires a gff, genbank and fasta file for the viral contig. Therefore, we have to extract these from the larger pharokka.gff and pharokka.gbk outputs.
The .gff file contains information about the gene positions and strands
The .gbk file contains information about the functional annotations of each gene
The fasta file contains the nucleotide sequence
Exercise - extracting contig information
We need 3 pieces of information about your pet contig to use the pharokka plotter
- contig.gff : extracted from the pharokka.gff
- contig.gbk : extracted from the pharokka.gbk
- contig.fasta : nucl. sequence extracted from the filtered assembly
Extract the functional annotation information for your contig from the
pharokka.gffandpharokka.gbkfiles and the contig nucleotide sequence from the fasta file
Gff and fasta files are easy to pull information from so we can just grep or sed the contig directly into an output file
Extract contig.gff
grep "contig_xxxx" pharokka.gff > contig_xxxx.gff # for example mkdir -p ./1.4_annotation/10_pharokka/11_selected_contig # get the contig.gff grep "contig_827" ./1.4_annotation/10_pharokka/pharokka.gff > ./1.4_annotation/10_pharokka/11_selected_contig/contig_827.gff
Extract contig fasta
# if your fasta file is in multi-line format # this tells sed to print between "contig_1026" and the next ">", including both patterns # `head` removes the last line (the second header) sed -n '/contig_1026/,/>/p' phage_contigs.fasta | head -n -1 # for example: sed -n '/contig_827/,/>/p' ./1.2_assembly/10_results_assembly_flye/cross_assembly/assembly.fasta | head -n -1 > ./1.4_annotation/10_pharokka/11_selected_contig/contig_827.fasta
Genbank files are a bit more difficult to extract information from but they are formatted sequentially by records. Luckily for us, there are pre-built modules in the biopython library to work with genbank files. SeqRecord and Bio.SeqIO.parse
If you head the pharokka.gbk file, you might see how the records are structured:
LOCUS contig_1026 35733 bp DNA linear PHG 06-SEP-2024
DEFINITION contig_1026.
ACCESSION contig_1026
VERSION contig_1026
KEYWORDS .
SOURCE .
ORGANISM .
.
FEATURES Location/Qualifiers
CDS complement(618..749)
/ID="contig_1026_CDS_0001"
/transl_table=11
/phrog="No_PHROG"
/top_hit="No_PHROG"
/locus_tag="contig_1026_CDS_0001"
/function="unknown function"
/product="hypothetical protein"
/source="Pyrodigal-gv_0.3.1"
/score="3.3"
/phase="0"
/translation="MTRWNTTLAVYEIWTGTQWQAVASSTYSINYLIVAGGASGAHY*"
You can use the python library Biopython to extract your contig from .gbk files. The whole contig is called a “record” - see the biopython SeqRecord class page for what each element in the record is called, You could use Bio.SeqIO.parse to iterate through these records and Bio.SeqIO.write to write out the record you want. The Biopython library is extensive and very useful for parsing sequencing files (fasta, fastq, genbank etc) within your python scripts.
biopython script to extract contig.gbk (genbank)
#!/usr/bin/python3 from Bio import SeqIO import sys # read files in as variables input_gbk = sys.argv[1] output_gbk = sys.argv[2] contig = sys.argv[3] # parse the genbank and write output for record in SeqIO.parse(input_gbk, "genbank"): # print(record.id) if record.id == contig: SeqIO.write(record, output_gbk, "genbank")
Once we have our fasta, gff and genbank files, we can use pharokka_plotter.py to plot our pet contig. pharokka_plotter.py requires the same conda environment as pharokka. So, to to activate the environment use the same commands you used for pharokka. Feel free to experiment with the different options given in the manual. The base usage is:
pharokka_plotter.py -i input.fasta -n pharokka_plot --gff pharokka.gff --genbank pharokka.gbk
You no longer need the pharokka database and we recommend modifying the following SBATCH parameters #SBATCH --mem=10G
Exercise - plotting
Plot the genome annotations for your pet contig. For the sbatch script below, you will have to change the contig name to your pet contig.
Make sure to add your plot into your lab book!
sbatch script for all the extraction steps + pharokka_plotter
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=10 #SBATCH --partition=short,standard,interactive #SBATCH --mem=10G #SBATCH --time=2:00:00 #SBATCH --job-name=pharokka_1 #SBATCH --output=20_selected_contig/pharokka_plotter.slurm.%j.out #SBATCH --error=20_selected_contig/pharokka_plotter.slurm.%j.err assembly='../1.3_virus_identification/30_filter_contigs/assembly.fasta' outdir='20_selected_contig' # CHANGE THIS CONTIG NAME contig_name="contig_71" mkdir -p $outdir # get the contig.gff and contig.fasta grep $contig_name 10_pharokka/results/pharokka.gff > $outdir/${contig_name}.gff sed -n '/$contig_name/,/>/p' $assembly | head -n -1 > $outdir/${contig_name}.fasta # next, we get the contig.gbk using a python script # change the names accordingly # activate the python virtual environment with the packages we need source ../py3env/bin/activate # the inputs for the following python script should be # python3 script.py input.gbk output.gbk $contig_name input_gbk='10_pharokka/results/pharokka.gbk' output_gbk='20_selected_contig/${contig_name}.gbk' python3 ../python_scripts/1.4_extract_contig.py $input_gbk $output_gbk $contig_name deactivate # Then we run pharokka plotter on our selected contig source /vast/groups/VEO/tools/anaconda3/etc/profile.d/conda.sh && conda activate pharokka_v1.7.1 # define all your file paths for readability outdir='20_selected_contig/' fasta='20_selected_contig/${contig_name}.fasta' gff='20_selected_contig/${contig_name}.gff' gbk='20_selected_contig/${contig_name}.gbk' pharokka_plotter.py -i $fasta -n $outdir/pharokka_plot --gff $gff --genbank $gbk conda deactivate
The final plot might look something like this:
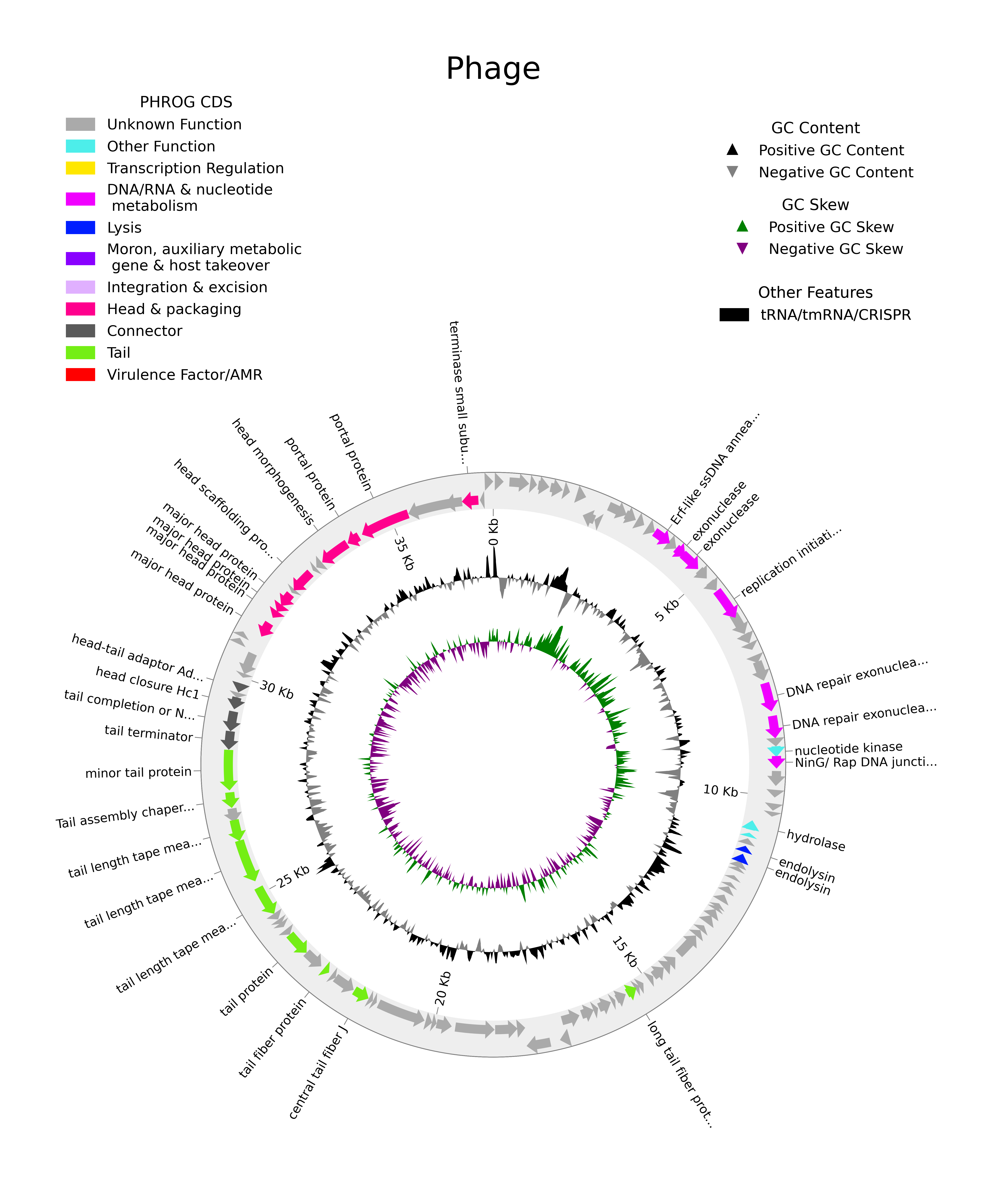
Interpreting your contig
With functional annotation we can begin to get an insight into our viruses to piece together information about their lifestyles, hosts interactions etc, what type of genes they have. You’ll find that most genes on viral contigs are not actually annotated - this is because 1) viruses evolve very quickly and assigning gene annotations by homology is difficult, and 2) viruses are highly mosaic - they pick up and lose genes from their hosts and other viruses, meaning not all viruses have all the same genes and viral gene databases do not always account for their variability. The creation of newer tools like phold aid in this by using structural homologs to assign gene annotation.
Note : We have phold installed on Draco, if you would like to experiment with it for your project! For example, you might pick a contig that is NOT well annotated and see how many extra genes you can annotate using structural homology
Exercise - Interpret your contigs
- How many structural genes are annotated?
- Describe at least 2 different types of structural genes a) Where are they placed in your genome? b) To which part of phage structure do they belong? (capsid, tail etc) c) What other viruses have these structural features?
- Describe the role of 1 replication gene a) What is the function of the gene? b) What part of the replication cycle is it used? c) How does it interact with the host genes (if they do)
- Describe 1 or more interesting genomic features
- CRISPR arrays, tRNA, virulence factors etc
- To the best of your ability, infer how this virus might be interacting with its host.
- You might investigate clues temperate/lytic lifestyles, auxiliary metabolic genes, anti-crisprs etc
Key Points
Functional annotation of viral genomes can give clues about viral lifestyle and host interactions
Viral taxonomy and phylogeny I
Overview
Teaching: 60 min
Exercises: 120 minObjectives
Understand the differences between taxonomic approaches for viral and cellular organisms
Explain the challenges with viral taxonomy, and how they may be overcome
![]()
How are viruses taxonomically classified?
There is no single method to classify the taxonomy of viruses. Many experts from the global virology community have done their part by classifying viruses according to their specific knowledge. This has generated a patchwork of methods that capture the features of different viral lineages and generate meaningful taxa that are in agreement with biology. With the advancement of viromics and the discovery of viruses by their genome sequences only, new methods are necessary to classify viruses based on their sequences, similar to approaches for cellular organisms.
A widely accepted approach for sequence-based taxonomic classification is by selecting a marker gene that is shared by all organisms, creating a multiple sequence alignment and phylogenetic tree, and identifying taxa as characteristic branches or lineages in the tree. This approach can be applied to all cellular organisms including bacteria, archaea, and eukaryotes, particularly using with ribosomal genes such as 16S small subunit in prokaryotes or the 18S in eukaryotes. As no marker gene is universally conserved in all viruses, this approach is only possible in subgroups of viruses. The lack of a universal genomic feature is thought to reflect their multiple evolutionary origins.
Bioinformaticians have developed many methods to circumvent the lack of a universal gene, for example, by cluster viral sequences. However, so far these methods have not been widely adopted for official ICTV virus taxonomy.
One popular method in the bacteriophage field is the gene-sharing network. This involves creating a network where nodes are viral genomes and edges represent shared gene families between these genomes. Tight clusters in this gene-sharing network represent groups of viral genomes that share many genes, and those could be interpreted as taxonomic groups. Networks can be built with different gene-sharing cutoffs, corresponding to different taxonomic ranks, where closely related viruses (species, genera) share more genes than distant ones (families). Tools like VICTOR and vConTACT3 work this way.
As more and more viruses are sequenced and we get a better view of the virosphere, marker genes are making a comeback. Although a universal marker gene shared by all viruses does not exist, marker genes are certainly shared by viruses of lower-ranking taxa (species, genera, families, orders, and in some cases above). Detecting the marker gene is evidence that a virus belongs to a given taxon, and phylogenetic trees can help resolve the lower-level taxonomy, just like ribosomal marker gene trees for cellular organisms. Tools like vClassifier and geNomad use marker gene approaches.
In the practical section of this day, we will be using marker gene methods and building a gene sharing network to classify the viruses identified in our metaviromes. Examples of widely used marker genes are for phages include the terminase large subunit (terL), major capsid protein (mcp) and DNA polymerase B (PolB).
Exercise - An overview of viral taxonomy
Check out the ICTV website: https://ictv.global/.
Discuss with your fellow students and write down your answers:
- What is ICTV? (not just a TV channel featuring polar bears)
- How many taxonomic ranks are available to classify the virosphere?
- What is a realm?
- How many viral genera are there?
- Pick one marker gene and describe how it functions in the virus-host interaction, which taxonomic rank it can/cannot identify.
Read the following sections from the review “Global Organization and Proposed Megataxonomy of the Virus World” by Koonin et al.:
- The Baltimore classes of viruses, virus hallmark genes, and major evolutionary trends in the virus world
- Evolutionary links among viruses within and across the Baltimore classes, section: Double-Stranded DNA Viruses
Discuss with your fellow students and write down your answers:
- What are the Baltimore Classes, and what are they based on?
- What triggered the change in viral taxonomy?
- What are the pros and cons of a “genomic taxonomy”?
Key Points
Viruses have multiple origins, so there is no universal marker gene
Viral taxonomy is based on many different methods
Gene-sharing networks and marker genes are popular methods for bacteriophage taxonomy
Viral taxonomy and phylogeny II
Overview
Teaching: 210 min
Exercises: 0 minObjectives
Run vConTACT3 to work out the taxonomy of your viruses
Interpret this taxonomy
Compare with relatedness of viruses based on the terL gene
What kind of phages exist in your dataset?
For this task, we will first build a phylogenetic tree using the terL marker gene, and second build a gene-sharing network using vConTACT3. Lastly, we will compare the taxonomic assignments given by vConTACT3 and the terL tree for a few viruses.
TerL phylogenetic tree
The terminase large subunit is a widely used marker gene for phages. This protein packages the DNA into an empty pro-capsid. It has two parts: 1) an ATP driven motor for viral DNA translocation and 2) a endonuclease to cleave the viral DNA to signal the end of the packaging reaction, once the capsid is full. TerL is quite essential in the assembly of full icosahedral capsids, and therefore makes a good marker gene for the Caudoviricetes order. Consider also that some phages do not require, and therefore, do not encode a terL gene.
Basics of making a tree
- Start with amino acid sequences in a fasta file
- Make a multiple sequence alignment (MSA) - this identifies biologically informative positions for tree inference
- INSPECT your MSA - you might need to trim poorly aligned columns
- Build a tree - there are several tree building algorithms - we will use maximum likelihood
Exercise - Make a terL phylogenetic tree with your sequences
For this exercise, we will use the ICTV reference phages. We have extracted the terL amino acid sequences from the ICTV reference phages using pharokka, and pre-built a multiple sequence alignment. You will have to add your sequences to this alignment using mafft and then trim the alignments using trimAl and build a tree using FastTree 2. The solution sbatch script at the bottom of the tree-making section includes all the tree-making steps.
To get a fasta file of your terL amino acid sequences (output by Pharokka) and locate the pre-built MSA
# location of the terL sequences from pharokka output ./1.4_annotation/10_pharokka/terL.faa # location of the reference pre-built MSA /vast/groups/VEO/shared_data/Viromics2025_workspace/data/alignments/terL_ICTV_ref_phage_alignment.fasta # copy the terL alignment to your own directory mkdir -p viromics/data/alignments # make a directory if it doesn't exist cp /vast/groups/VEO/shared_data/Viromics2025_workspace/data/alignments/terL_ICTV_ref_phage_alignment.fasta viromics/data/alignmentsTo add your terL sequences to the reference alignment using mafft. You need the following command and it will take ~22min
/home/groups/VEO/tools/mafft/v7.505/bin/mafft --reorder --keeplength --addfragments contigs_terL.fasta reference_alignment.fasta > new_MSA.fastaTo trim your alignment using TrimAl (-gappyout)
trimal -in new_MSA.fasta -out new_MSA_trimmed.fasta -gappyoutTo build a tree using FastTree.
/home/groups/VEO/tools/fastTreeMP/v2.1.11/FastTreeMP -lg -pseudo < new_MSA_trimmed.fasta > new_MSA_trimmed.tree # -lg : Uses the LG model. Note: the LG model is an updated model that describes how likely it is that one amino acid is replaced by another based on patterns found in real protein families. The default model for Fasttree is the JTT - which is older but similar model. # -pseudo : Adds pseudo counts (for gappy alignments)
TerL tree outputs
Phylogenetic trees come in several output types but here the above commands produce a tree in a newick format. This is a text file and you can open it with any text editor to see what it looks like. It takes the shape: (A:0.1, B:0.2, (C:0.3, D:0.4)E:0.5)F;
The final terL tree might look something like this:
This .tree file can be opened with dendroscope (if you downloaded it locally) or iTOL or another tree-visualization software HOWEVER the full terL tree we will produce will have 5000+ leaves, which will be difficult to load into tree-viewers and might crash your computer when trying to find your viruses.
Instead, you could post-process the tree using the ete3 library in Python.
Exercise - Post-process large tree –> smaller tree
There are a few ways to post-process trees to make them viewable or to highlight our viruses of interest.
- One way would be build a script that takes the input of a single contig and the tree file and pruning the tree around the contig to a certain number of the closest reference viruses. Pruning a tree means only certain clades or leaves are left.
- Instead of pruning, you can also “collapse” clades to make the tree manageable to view. For this, clades are collapsed into a single leaf that replaces them. In very large trees, you will probably encounter large clades that are far away from your sequences of interest that can be collapsed and replace. For this, you might want to give an input of all your viruses of interest.
We’ve built two python scripts using this library to shrink the size of tree outputs. The locations of the tree-pruning scripts will be in your python_scripts directory python_scripts/1.5_collapse_non_target_clades.py and python_scripts/1.5_trim_tree_to_500_neighbors.py.
1.5_trim_tree_to_500_neighbors.py will trim your tree around a contig of your choice to the closest 500 neighbours. 1.5_collapse_non_target_clades.py will collapse clades that don’t contain viruses from our dataset. These scripts also include a section to generate ITOL annotation files.
python script to trim tree around 1 contig
# trim_tree_to_500_neighbors.py from ete3 import Tree import sys def trim_tree(input_tree_file, target_leaf_name, output_tree_file, itol_output_file=None, num_neighbors=500): tree = Tree(input_tree_file, format=1) if not tree.search_nodes(name=target_leaf_name): raise ValueError(f"Leaf '{target_leaf_name}' not found in the tree.") target_leaf = tree&target_leaf_name leaves = [(leaf, target_leaf.get_distance(leaf)) for leaf in tree.iter_leaves()] leaves.sort(key=lambda x: x[1]) # Get ~500 closest neighbors including the target leaf closest_leaves = set([leaf.name for leaf, dist in leaves[:num_neighbors]]) # Prune the tree pruned_tree = tree.copy() pruned_tree.prune(closest_leaves, preserve_branch_length=True) pruned_tree.write(outfile=output_tree_file, format=1) if itol_output_file: user_colour = "#079907" # Green for user nodes with open(itol_output_file, "w") as f: f.write("DATASET_SYMBOL\n") f.write("SEPARATOR TAB\n") f.write("DATASET_LABEL\tUser-selected leaves\n") f.write("COLOR\t#00cc00\n") f.write("DATA\n") f.write(f"{target_leaf_name}\t3\t2\t{user_colour}\t1\t1\n") # symbol star=3, size=2, fill=1,position=1 if __name__ == "__main__": if len(sys.argv) not in (4, 5): print("Usage: python trim_tree_to_500_neighbors.py input_tree.nwk target_leaf_name output_tree.nwk [itol_output.txt]") sys.exit(1) itol_output = sys.argv[4] if len(sys.argv) == 5 else None trim_tree(sys.argv[1], sys.argv[2], sys.argv[3], itol_output)
python script to collapse clades except our viruses
# collapse_non_target_clades.py from ete3 import Tree import sys def collapse_large_non_target_clades(input_tree_file, user_leaves_file, output_tree_file, itol_output_file=None, threshold=100): tree = Tree(input_tree_file, format=1) with open(user_leaves_file) as f: target_leaves = set(line.strip() for line in f if line.strip()) collapsed_info = [] node_counter = [1] def process_node(node): leaves_in_subtree = set(leaf.name for leaf in node.iter_leaves()) if len(leaves_in_subtree) > threshold and not (leaves_in_subtree & target_leaves): collapsed_name = f"collapsed_node_{node_counter[0]}" node.name = collapsed_name node_counter[0] += 1 collapsed_info.append((collapsed_name, len(leaves_in_subtree))) node.children = [] else: for child in node.children: process_node(child) process_node(tree) tree.write(outfile=output_tree_file, format=1) if itol_output_file: # collapsed_colour = "#878787" # Blue for collapsed nodes user_colour = "#079907" # Green for user nodes # with open(itol_output_file, "w") as f: # f.write("DATASET_TEXT\n") # f.write("SEPARATOR TAB\n") # f.write("DATASET_LABEL\tCollapsed Nodes\n") # f.write(f"COLOR\t{collapsed_colour}\n") # f.write("DATA\n") # for node_name, size in collapsed_info: # if not node_name: # continue # Skip blank node names just in case # f.write(f"{node_name}\t{collapsed_colour}\tClade ({size} leaves)\n") # Write user leaf highlight using green stars (iTOL DATASET_SYMBOL) # highlight_file = itol_output_file.replace(".txt", "_user_symbols.txt") with open(itol_output_file, "w") as f: f.write("DATASET_SYMBOL\n") f.write("SEPARATOR TAB\n") f.write("DATASET_LABEL\tUser-selected leaves\n") f.write("COLOR\t#00cc00\n") f.write("DATA\n") for leaf in sorted(target_leaves): f.write(f"{leaf}\t3\t2\t{user_colour}\t1\t1\n") # symbol star=3, size=2, fill=1,position=1 if __name__ == "__main__": if len(sys.argv) not in (4, 5): print("Usage: python collapse_non_target_clades.py input_tree.nwk user_leaves.txt output_tree.nwk [itol_output.txt]") sys.exit(1) itol_output = sys.argv[4] if len(sys.argv) == 5 else None collapse_large_non_target_clades(sys.argv[1], sys.argv[2], sys.argv[3], itol_output)
Exercise - Post-process your tree
Use the below sbatch script make your tree and post-process it. Note: For some exercises today, pick a pet contig (maybe the same as the one yesterday!). You will have change the contig name in the sbatch scripts accordingly.
Please pause once you have made the trees! We will visualize the tree together with a demo in itol so that you can make nice graphics to include in your lab books!
sbatch script to make tree and post-process it
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=10 #SBATCH --partition=short,standard,interactive #SBATCH --mem=50G #SBATCH --time=2:00:00 #SBATCH --job-name=terL_tree #SBATCH --output=./10_terL_tree/terL.slurm.%j.out #SBATCH --error=./10_terL_tree/terL.slurm.%j.err # Run mafft to add the sequences mafft="/home/groups/VEO/tools/mafft/v7.505/bin/mafft" new_seqs="../1.4_gene_annotation/10_pharokka/results/terL.faa" terl_aln="../data/alignments/phylogenetic_alignments/terL_ICTV_ref_phage_alignment.fasta" # have to add sequences to untrimmed alignment, since mafft doesn't know what was trimmed $mafft --add $new_seqs --reorder $terl_aln > ./10_terL_tree/terL_MSA.fasta # Trim the alignment using trimAl trimal="/home/groups/VEO/tools/trimal/v1.5.0/trimal/source/trimal" $trimal -in ./10_terL_tree/terL_MSA.fasta -out ./10_terL_tree/terL_MSA_trimmed.fasta -gappyout # Build a tree using fasttree fastTreeMP="/home/groups/VEO/tools/fastTreeMP/v2.1.11/FastTreeMP" $fastTreeMP -lg -pseudo < ./10_terL_tree/terL_MSA_trimmed.fasta > ./10_terL_tree/terL_MSA_trimmed.tree source ../py3env/bin/activate # change your contig name here contig_name=contig_71_CDS_0091 # prune the tree based on your selected contig python3 ../python_scripts/1.5_trim_tree_to_500_neighbors.py ./10_terL_tree/terL_MSA_trimmed.tree $contig_name ./10_terL_tree/terl_${contig_name}_pruned.tree ./10_terL_tree/${contig_name}_itol_annotation.txt # get all your viruses into user_leaves.txt grep ">" ../1.4_gene_annotation/10_pharokka/results/terL.faa | sed 's/>//g' |sed 's/ .*$//' > ./10_terL_tree/user_leaves.txt # collapse tree branches except user defined leaves python3 ../python_scripts/1.5_collapse_non_target_clades.py ./10_terL_tree/terL_MSA_trimmed.tree ./10_terL_tree/user_leaves.txt ./10_terL_tree/terl_collapsed.tree ./10_terL_tree/collapsed_itol_annotation.txt deactivate
vConTACT3
vConTACT3 has an underlying assumption that the fraction of shared genes between two viruses represents their evolutionary relationship. The vConTACT3 gene-sharing network closely correlates with the ICTV taxonomy.
Exercise - run vConTACT3
Run vcontact3 on your virome dataset
You will need the following commands for the conda environment and database
source /vast/groups/VEO/tools/miniconda3_2024/etc/profile.d/conda.sh conda activate vcontact3_3.0.5-0 # Need to use with db path? vcontact3 --db-path /veodata/03/databases/vcontact3/v20250721/See your options:
vcontact3 run --helpExample command
Note: Take care to request enough memory (RAM) for processing your data by adjusting the –mem=xxG command in your sbatch script. vConTACT3 loads a full viral network into a graph
vcontact3 run --nucleotide virus_genomes.fasta --output output_directory --db-path /veodata/03/databases/vcontact3/v20250721/ -e cytoscape # other commands you might use # -t : threads # --distance-metric : {VirClust,SqRoot,Shorter,Jaccard} # --min-shared-genes : minimum number of shared genes for two genomes to be connected # -e : exporting formats/files
!! Copy this file over to your workspace by copying these commands !!
cd ~/Viromics2025_Workspace source py3env/bin/activate pip install h5py # we have to install a new python package called h5py cp /vast/groups/VEO/shared_data/Viromics2025_workspace/python_scripts/1.5_extract_contacts.py python_scripts/1.5_extract_contacts.py cp /vast/groups/VEO/shared_data/Viromics2025_workspace/sbatch_scripts/1.5_20_vcontact.sbatch 1.5_taxonomy/1.5_20_vcontact.sbatch
sbatch script to run vcontact3
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=10 #SBATCH --partition=short,standard,interactive #SBATCH --mem=50G #SBATCH --time=2:00:00 #SBATCH --job-name=vcontact3 #SBATCH --output=./2.2_taxonomy/20_vcontact_results/vcontact3.slurm.out.%j #SBATCH --error=./2.2_taxonomy/20_vcontact_results/vcontact3.slurm.err.%j # activate conda environment source /vast/groups/VEO/tools/miniconda3_2024/etc/profile.d/conda.sh conda activate vcontact3_3.0.5-0 database='/veodata/03/databases/vcontact3/v20250721/' assembly='./1.3_virus_identification/40_results_filter_contigs/assembly.fasta' outdir='./2.2_taxonomy/20_vcontact_results' #options # -e : how do you want the output formatted? See the vcontact3 help for more options vcontact3 run --nucleotide $assembly --output $outdir --db-path $database -e cytoscape # Below we will convert the VContact3 results to a more readable format. # change the contig_id below to your pet: contig_id="contig_728" source ../py3env/bin/activate python3 ../python_scripts/1.5_extract_contacts.py $contig_id ${contig_id}_0.5_sharedgenes.csv
Output hints
20_vcontact_results/exports/final_assignments.csv–> taxonomic assignments for everything (search for “contig”)20_vcontact_results/exports/contig_id_0.5_sharedgenes.csv–> shared genes for your contig at 50% identity20_vcontact_results/exports/networks/part1.cyjsfiles is network file for Cytoscape- The rest of files ending with
.h5is a heirarchical binary format for storing large amounts of scientific/meta data.
Exercise - comparing your taxonomic annotations
General Questions
- What percentage of your total viral contigs were classified by vConTACT3?
- How can you judge the accuracy of your taxonomic classifications?
- What is the maximum taxonomic distance between viruses that are still connected in the vConTACT3 graph?
- What is the taxonomy classifcation of your pet contig from vConTACT3 and the terL tree? (if at all)
- How many genes are shared with known reference viruses? (vConTACT3 results)
- If your classifications are/were different between the terL tree and the vConTACT3 - which classification would you trust more?
Group Discussions
- Explore the cytoscape network visualization and/or terL tree together - include a graphic of at least 1 tree
- What do long branches on your terL tree mean?
- What does a rooted versus an unrooted tree represent?
- What are the limitations of using the terL tree? and could you overcome these limitations?
Hint on querying pickle files using python
import pandas as pd # read in the shared genes pickle file # this pickle file contains genes shared at even 30% identity - there are other files for 40, 50 ,60 and 70% identity df_3 = pd.read_pickle("HMMprofile.0.3_SqRoot_shared_genes.pkl.gz") df_3 # check how many genes contig_518 shares with the other contigs df_3_contig_518 = df_3.loc[df_3['contig_518'] > 0, 'contig_518'] df_3_contig_518
Key Points
VConTACT3 is used to classify viral taxonomy of sequences based on the number of shared genes
Marker genes such as the terminase large subunit (terL) can also be used to judge how related viruses are and in some cases classify the taxonomy as lower taxa ranks
Visualizing viral taxonomy
Overview
Teaching: 0 min
Exercises: 90 minObjectives
Plot the network of closely related viruses created by vConTACT3
This section is suggested as homework.
Today, you taxonomically annotated your phage contigs with vConTACT3.
The tool applies a gene-sharing network approach by computing the number of homologous genes between two viral sequences.
Based on this information, it integrates unseen contigs into a reference network of taxonomically classified phages, and then uses information about related viruses in the network to infer a taxonomic classification.
The resulting network, which contains both the reference phages and our assembled contigs, can be found in the output file graph.cyjs in your vConTACT3 results folder.
This file contains the network encoded in JSON format, which can be parsed with the Python standard library package json.
Python also provides several tools for handling and analyzing networks. In this section, you will use the NetworkX package to visualize the network of phages. The goal is to get an idea of the taxonomic diversity of the contigs in our dataset, and how it compares to reference phages in the database. You can either focus on a single contig and its closely related phages (close network neighborhood) or plot the whole network to get an overview of the full virosphere (at least the viruses in the reference database).
NetworkX provides several functions for drawing the network. Our network only consists of nodes (phages) and weighted edges (number of shared genes) between them, without any layout information (where to position the nodes). There are many algorithms for finding a visually pleasing layout for a given network. The Kamada-Kawai layout and the spring layout both employ a physical force-based simulation that optimizes the distance or attraction between node pairs. In our network, the number of shared genes between two nodes serves as a measure of attraction. The spring layout is computationally less demanding and should be used for the visualization of the complete network.
Making these plots involves a fair amount of programming and testing your code. This homework is not so much about figuring out the code but to introduce you to networkx as a tool for network analysis and visualization, and create a visualization which can confer the relational character of the data better than a table could. You can either try to figure out the code for this homework for yourself or start with one of the solutions and try to adjust or improve it. The goal is for you to end up with a picture of the network of phages which confers the idea of the algorithm VConTACT3 implements.
# you have to add networkx to the virtual environment first
import networkx as nx
# the json package is part of the standard library
import os, sys, json
# parse the json file and create a networkx graph from it
with open(graph_filename) as json_file:
graph_json = json.load(json_file)
# the following lines are necessary for compatibility with networkx
graph_json["data"] = []
graph_json["directed"] = False
for node in graph_json["elements"]["nodes"]:
# the 'value' attribute will be used for naming the nodes
node["data"]["value"] = node["data"]["id"]
# create a networkx graph from the graph_json dictionary
g = nx.cytoscape_graph(graph_json)
# use draw_networkx_nodes(...) and draw_networkx_edges(...) to draw the graph
# use g.subgraph(...) or g.edge_subgraph(...) to select a subgraph of interest
python script for plotting the local neighborhood of your selected contig
import os, sys, json import networkx as nx import matplotlib.pyplot as plt import matplotlib.patches as mpatches import matplotlib as mpl # the keys to access taxonomic ranks of the phages in the graph ranks = ["order", "class", "phylum"] # this function looks for the lowest available rank according to the ones defined in the ranks variable def get_lowest_tax(node): for r in ranks: if r in node.keys(): return node[r] return "none" def main(): graph_filename = os.path.abspath(sys.argv[1]) assert graph_filename.endswith(".cyjs") out_filename = os.path.abspath(sys.argv[2]) assert out_filename.endswith(".png") contig_id = sys.argv[3] with open(graph_filename) as json_file: graph_json = json.load(json_file) # set for compatibility with networkx graph_json["data"] = [] for node in graph_json["elements"]["nodes"]: # assign "value" attribute for compatibility node["data"]["value"] = node["data"]["id"] # assign lowest availble taxonomic rank with our function node["data"]["lowest_tax"] = get_lowest_tax(node["data"]) g = nx.cytoscape_graph(graph_json) # find your favourite contig and get its internal node id contig_id_node = -1 for node in g.nodes(data="name"): if node[1] == contig_id: contig_id_node = node[0] # raise an error, if the contig could not be found if contig_id_node == -1: raise(AssertionError(f"Could not find {contig_id} in the graph")) # get all nodes connected to the selected contig and compute the corresponding subgraph node_set = {contig_id_node}.union({n for n in g.neighbors(contig_id_node)}) subgraph = g.subgraph(node_set) # get all taxa in the subgraph taxa = nx.get_node_attributes(subgraph, "lowest_tax") # set up a mapping from node to color based on the taxonomic rank unique_taxa = np.unique([t for t in taxa.values()]) taxa_to_color = {t:mpl.colormaps["tab20"](i) for i, t in enumerate(unique_taxa)} colors = {n:taxa_to_color[t] for n, t in taxa.items()} # compute a positional layout using the kamada-kawai algorithm pos = nx.kamada_kawai_layout(subgraph) # set colors for nodes. use the taxonomic information to color the reference nodes names = nx.get_node_attributes(subgraph, "name") colors = [('seagreen' if names[n] == contig_id else 'red') if names[n].startswith('contig') else colors[n] for n in subgraph.nodes()] # draw the network using the functions networkx provides nx.draw_networkx_edges(subgraph, pos=pos, width=0.05, alpha=0.4) nx.draw_networkx_nodes(subgraph, pos=pos, alpha=0.7, node_size=100, node_color=colors) nx.draw_networkx_labels(subgraph, pos=pos, labels=names, font_size=3) # create rectangles for a legend connecting taxa with their colors in the graph patches = [mpatches.Patch(color=c, label=l, alpha=0.6) for l,c in taxa_to_color.items() if l!='none'] + \ [mpatches.Patch(color='red', label='our contigs'), mpatches.Patch(color='green', label='selected contig')] plt.legend(handles=patches, loc='upper right', framealpha=0.5, frameon=True, prop={'size': 5}) ax = plt.gca() ax.axis('off') plt.tight_layout() plt.savefig(out_filename, dpi=700) if __name__ == "__main__": main()
python script for plotting the complete network of phages
import os, sys, json import networkx as nx import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as mpatches import matplotlib as mpl # the keys to access taxonomic ranks of the phages in the graph ranks = ["order", "class", "phylum"] # this function looks for the lowest available rank according to the ones defined in the ranks variable def get_lowest_tax(node): for r in ranks: if r in node.keys(): return node[r] return "none" def main(): # parse first parameter: path to the graph file graph_filename = os.path.abspath(sys.argv[1]) assert graph_filename.endswith(".cyjs") # parse second parameter: path to the output file out_filename = os.path.abspath(sys.argv[2]) assert out_filename.endswith(".png") # third parameter: the id of your favourite contig to highlight in the network contig_id = sys.argv[3] # parse the json file containing the graph generated by VContact3 with open(graph_filename) as json_file: graph_json = json.load(json_file) # set for compatibility with networkx graph_json["data"] = [] for node in graph_json["elements"]["nodes"]: # assign "value" attribute for compatibility node["data"]["value"] = node["data"]["id"] # assign lowest availble taxonomic rank with our function node["data"]["lowest_tax"] = get_lowest_tax(node["data"]) for edge in graph_json["elements"]["edges"]: # add "weight attribute for compatibility edge["data"]["weight"] = float(edge["data"]["distance"]) # assign "attraction" attribute as inverse of "distance" for the position finding algorithm (spring) edge["data"]["attraction"] = 1-edge["data"]["weight"] # generate a networkx graph object from the json object g = nx.cytoscape_graph(graph_json) # find your favourite contig and get its internal node id contig_id_node = -1 for node in g.nodes(data="name"): if node[1] == contig_id: contig_id_node = node[0] # raise an error, if the contig could not be found if contig_id_node == -1: raise(AssertionError(f"Could not find {contig_id} in the graph")) # limit our drawing to nodes actually connected to anything. connected_nodes = {n for n in g.nodes() if len(g.adj[n])>0} subgraph = g.subgraph(connected_nodes) # get all taxa in the subgraph taxa = nx.get_node_attributes(subgraph, "lowest_tax") # the number of taxa could be above the number of colors in a colormap, combine two for more colors colormap = [mpl.colormaps["tab20"](i) for i in range(20)] + [mpl.colormaps["tab20b"](i) for i in range(20)] # set up a mapping from node to color based on the taxonomic rank unique_taxa = np.unique([t for t in taxa.values()]) taxa_to_color = {t:colormap[i] for i, t in enumerate(unique_taxa)} colors = {n:taxa_to_color[t] for n, t in taxa.items()} # compute positions for the nodes in the network. The spring algorithm is fast, but not so pretty. # sadly, networkx has no good alternatives for large networks. pos = nx.spring_layout(subgraph, k=1/100000, weight="attraction", iterations=50) # The produced layout is very concentrated in the center. Transform the coordinates for zooming in. pos = {k:np.array(p)-np.array(p)*np.log(np.linalg.norm(p)) for k,p in pos.items()} # get the "name" attribute of all nodes. We can use it to identify our contigs names = nx.get_node_attributes(subgraph, "name") # get the subgraph containing the reference set of phages and assign colors to the nodes according to the taxonomic rank nodes_ref = {n for n in subgraph.nodes() if not names[n].startswith("contig_")} subgraph_ref = subgraph.subgraph(nodes_ref) subgraph_ref_colors = [colors[n] for n in subgraph_ref.nodes()] # get the subgraph containing our contigs, we will color them all the same. nodes_contigs = {n for n in subgraph.nodes() if names[n].startswith("contig_")} subgraph_contigs = subgraph.subgraph(nodes_contigs) # get the subgraph of your favourite contig (only the contig :)) and the edge subgraph connecting the contig to the reference # we can use it to highlight the connections of the contig in the reference network subgraph_select = subgraph.subgraph({contig_id_node}) subgraph_neighbors = subgraph.edge_subgraph([(contig_id_node, n) for n in subgraph.neighbors(contig_id_node)]) # create a figure and axis with pyplot fig, ax = plt.subplots() # draw the reference network. first, we draw the edges and then the nodes. networkx also does this automatically. # read the comment of the next code block for setting the drawing order manually nx.draw_networkx_edges(subgraph, pos=pos, alpha=0.1, width=[1-subgraph[u][v]["weight"] for u,v in subgraph.edges()], node_size=10, edge_color="grey", ax=ax) nx.draw_networkx_nodes(subgraph_ref, pos=pos, alpha=0.6, node_size=10, node_color=subgraph_ref_colors, linewidths=0.0, ax=ax) # highlight your favourite contigs neighborhood by drawing the connecting edges and circles around the neighbor nodes # set_zorder tells matplotlib the order, in which objects are to be rendered. the values can be set arbitrarily as long as # they set up an order. edges_on_top = nx.draw_networkx_edges(subgraph_neighbors, pos=pos, alpha=0.6, width=0.02, node_size=10, ax=ax) edges_on_top.set_zorder(2) edges_on_top = nx.draw_networkx_nodes(subgraph_neighbors, pos=pos, linewidths=0.02, node_size=10, node_color='none', edgecolors="black", ax=ax) edges_on_top.set_zorder(2) # draw our contigs on top of everything else contig_nodes_collection = nx.draw_networkx_nodes(subgraph_contigs, pos=pos, alpha=0.9, node_size=10, node_color="red", linewidths=0.0, ax=ax) contig_nodes_collection.set_zorder(3) # add your favourite contig on top of that select_collection = nx.draw_networkx_nodes(subgraph_select, pos=pos, alpha=0.9, node_size=10, node_color="green", linewidths=0.0, ax=ax) select_collection.set_zorder(4) # create rectangles for a legend connecting taxa with their colors in the graph patches = [mpatches.Patch(color=c, label=l, alpha=0.6) for l,c in taxa_to_color.items()] + [mpatches.Patch(color='red', label='our contigs'), mpatches.Patch(color='green', label='selected contig')] ax.legend(handles=patches, loc='center right', framealpha=0.5, frameon=True, prop={'size': 5}) # do some adjustments to improve the plot, first remove outer borders ax.axis('off') # set the min and max of each axis, add a bit of free space on the upper xlim for the legend xs, ys = [p[0] for p in pos.values()], [p[1] for p in pos.values()] xmin, xmax, ymin, ymax = np.min(xs), np.max(xs), np.min(ys), np.max(ys) ax.set_xlim([xmin + 0.05*xmin, xmax + 0.5*xmax]) ax.set_ylim([ymin + 0.05*ymin, ymax + 0.05*ymax]) # save the figure with a high resolution to be able to see enough fig.savefig(out_filename, dpi=700) if __name__ == "__main__": main()
sbatch script for submitting the plotting script
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=2 #SBATCH --partition=short #SBATCH --mem=5G #SBATCH --time=00:10:00 #SBATCH --job-name=taxonomic_graph #SBATCH --output=./2.2_taxonomy/40_plot_networks/taxonomic_graph.slurm.%j.out #SBATCH --error=./2.2_taxonomy/40_plot_networks/taxonomic_graph.slurm.%j.err # activate the python virtual environment with the packages we need source ../py3env/bin/activate # in this sbatch script, its not necessarry to create the directory, # we already told sbatch to create it for the log files. mkdir -p ./2.2_taxonomy/40_plot_networks/ # define an array with contig ids to plot declare -a arr=("contig_10" "contig_109", "contig_164") # loop through the array for contig in "${arr[@]}" do # run our scripts for plotting the network around a contig of choice # PLOT CONTIG IN LOCAL GENE SHARING NETWORK python python_scripts/taxonomy/30_taxonomic_graph_local.py ../2.2_viral_taxonomy/02_vcontact3_results_new_contig_names/graph.cyjs ./2.2_taxonomy/40_plot_networks/"$contig"_graph_local.png $contig # PLOT CONTIG IN GLOBAL GENE SHARING NETWORK python python_scripts/taxonomy/30_taxonomic_graph_global.py ../2.2_viral_taxonomy/02_vcontact3_results_new_contig_names/graph.cyjs ./2.2_taxonomy/40_plot_networks/"$contig"_graph_global.png $contig done # deactivate the environment deactivate
Plot the network of closely related phages
You can choose to plot the whole network of all reference phages and contigs, or zoom in and plot a single contig and its neighborhood.
- Use the taxonomic information encoded in the network to color the nodes.
- Use draw_networkx_nodes and draw_networkx_edges to better access the plot attributes.
Key Points
The Python package NetworkX can be used to work with networks
The visualization of graphs usually requires the computation of positions for the nodes
Many of our contigs are close to Caudoviricitae, but we also have several connected groups of unclassified sequences
Host Prediction I
Overview
Teaching: 60 min
Exercises: 120 minObjectives
Understand how biological information is used to predict hosts
Understand the difficulties with host prediction
Learn about the new techniques that are being used for host prediction
![]()
Host prediction lecture
Listen to lecture by Varada and Malte (pay attention!!!) slides for host prediction
Questions
After listening to the lecture, please answer these questions:
- What are some biological interactions viruses have with their hosts? (hint: start with the infection cycle)
Pick one classical host prediction method:
- In brief, explain how this works
- What is the major challenge with this method?
- How can you be confident in your host prediction?
- Evaluate the following scenarios: a) Two viral contigs match to the same host during the host prediction b) One viral contig matches 2 hosts: s__Salinibacter ruber and s__Longimonas halophila
For the hands-on part - we will be using a tool called RaFAH. This tool uses random forest model machine learning models to predict hosts for phages. They train the ML model using the protein content of viral sequences and compare it with manually curated classical host predictions (CRISPR sequences, tRNA and homology based matches) and related other tools. Have a look into the RaFAH paper and focus on the introduction and Figures 1 and 2.
Questions
After going through the paper, please answer the following questions:
- Briefly discribe how RaFAH derives its predictions from a genome sequence.
RaFAH produces a probability score for each host genus in its training set and reports the genus with the maximum probability. In Figure 2, you can find how this score relates to precision and recall for the test dataset the authors used.
- Decide, which probability score you would use as a cutoff for predictions you would trust. Explain your decision.
Additional resources
- IBM link on Random Forest (RF): introduces RF and decision trees in a short and simple way
- Chapter on RF for Bioinformatics: explains how RF measures feature importance and describes Bioinformatic applications
- Chapter on Decision Trees and RF: describes decision trees and RF by direct application in python. Also, if you want a great introduction to machine learning in general and python programming, take a look at the whole book by Jake VanderPlas, which is freely available online
Key Points
Host Prediction II
Overview
Teaching: 0 min
Exercises: 300 minObjectives
Run RaFAH to predict a host genus for each contig.
Run BLASTn to find homologies between metagenome and metavirome.
Host prediction
Today, we will use the tool RaFAH to predict a genus of a putative host for our contigs. The tool predicts proteins in each viral sequence and then assigns them to a set of orthologous groups. The annotated proteins are then used to predict a host genus with a pretrained random forest model. This model matches the set of proteins with host proteins it was trained on.
After running RaFAH, we will compare the resulting prediction with the bacterial metagenome you briefly analyzed in one of last weeks homeworks. The bacterial metagenome was taxonomically annotated using GTDB. We will get into taxonomic classification of viruses tomorrow, for today it is important to know that there are different methods of taxonomic classification. RaFAH uses the NCBI taxonomy, so we will have to translate the output of RaFAH into the GTDB taxonomy to be able to compare the predictions with our bacterial metagenome.
Next, we will use BLAST as an alternative way of linking viruses to their hosts. With BLAST, we will align our viral contigs to putative bacterial and archael genomes (Metagenome-Assembled-Genomes, MAGS) to find sequence matches between the viruses and potential hosts.
Finally, we will combine the results from RaFAH and BLAST to compare the two methods and see how well they agree.
RaFAH
Exercise - Use RaFAH to predict hosts for our contigs
RaFAH requires a single file for each contig to run. You first have to write a python script which separates the combined assembly into single files. You can use the package biopython installed in your virtual environment for this:
import os, sys from Bio import SeqIO # define file paths from the arguments ... # loop through the records in the combined assembly with open(assembly_path) as handle: for record in SeqIO.parse(handle, "fasta"): # set a filename per record out_fasta = os.path.join(out_dir, f"{record.id}.fasta") # write the record to the file with open(out_fasta, "w") as fout: SeqIO.write([record], fout, "fasta")Next, you will write a python script, which translates the host genus predictions from the NCBI taxonomy into the GTDB taxonomy. You can copy the translation table from this location on draco:
$ cp /work/groups/VEO/shared_data/Viromics2024Workspace/2.1_host_prediction/ncbi_to_gtdb.csv ./2.1_host_prediction/10_rafah/ncbi_to_gtdb.csvThere are hundreds of thousands of taxa in both taxonomy schemes, so we need to efficiently map one onto the other. Here are some hints:
import os, sys import pandas as pd # Extract the genus part of the NCBI taxonomy. # This should correspond to RaFAH's output def get_ncbi_genus(s): for ss in s.split(";"): if ss.startswith("g__"): return ss[3:] return "none" # Extract the complete taxonomic classification up to genus from GTDB def get_gtdb_upto_genus(s): return s.split(";s__")[0] # set or get filenames from sys.argv and read tables with pandas ... # create a dictionary for efficient mapping between the two taxonomies translation_dict = {get_ncbi_genus(r["ncbi_taxonomy"]):get_gtdb_upto_genus(r["gtdb_taxonomy"]) for i, r in translate_df.iterrows()} # use the dictionary to translate the predictions in the RaFAH output table ...You can run the scripts in the same sbatch script as RaFAH. Remember to source and deactivate our python virtual environment accordingly. Here you can find a description of the parameters you can pass to RaFAH (the page is a bit hard to read). The tool is programmed in perl and you can find it here on draco:
# activate the conda environment with the dependencies RaFAH requires source /vast/groups/VEO/tools/miniconda3_2024/etc/profile.d/conda.sh && conda activate perl_v5.32.1 # set a variable to call the RaFAH script rafah='/home/groups/VEO/tools/rafah/RaFAH.pl' # create an output folder or use the one you set for the slurm logs: mkdir 10_results_hostprediction_rafah # run RaFAH with the appropriate file paths and arguments perl "$rafah" --predict --genomes_dir 10_results_hostprediction_rafah/split_contigs --extension .fastaRaFAH is computationally expensive and can use multiple threads. We recommend you set the following sbatch parameters:
- #SBATCH –cpus-per-task=32
- #SBATCH –partition=standard,short
- #SBATCH –mem=50G
RaFAH uses the random forest model to compute a probability for all host genuses included in its training. You can find these probabilities in the output file
*Host_Predictions.tsv. The file*Seq_Info_Prediction.tsvcontains per contig the genus with the highest probability.
- How many contigs have a probability score larger than your chosen cutoff?
- Does the probability score relate to the completeness of the contigs? (qualitative answer)
- Does the probablility score relate to the number of genes in the contigs? You can plot these against each other using the
*Seq_Info_Prediction.tsvfile.- What is the prediction of your chosen contig? Compared with the results from VContact3, does the prediction match your expectations? Do other contigs connected to your contig also share a common host prediction?
python script for splitting the assembly into separate files
import os, sys from Bio import SeqIO def main(): # define file paths from the arguments assembly_path = os.path.abspath(sys.argv[1]) assert assembly_path.endswith(".fasta") # set an output directory and create it if it does not exist out_dir = os.path.abspath(sys.argv[2]) if not os.path.exists(out_dir): os.makedirs(out_dir) # loop through the records in the combined assembly with open(assembly_path) as handle: for record in SeqIO.parse(handle, "fasta"): # set a filename per record out_fasta = os.path.join(out_dir, f"{record.id}.fasta") # write the record to the file with open(out_fasta, "w") as fout: SeqIO.write([record], fout, "fasta") if __name__ == "__main__": main()
python script for translating NCBI genus IDs to GTDB
import os, sys import pandas as pd # Extract the genus part of the NCBI taxonomy. # This should correspond to RaFAH's output def get_ncbi_genus(s): for ss in s.split(";"): if ss.startswith("g__"): return ss[3:] return "none" # Extract the complete taxonomic classification up to genus from GTDB def get_gtdb_upto_genus(s): return s.split(";s__")[0] def main(): # set the filename of the rafah output file containing the best prediction per contig rafah_filename = os.path.abspath(sys.argv[1]) assert rafah_filename.endswith(".tsv") # set the filename of the translation table with NCBI and GTDB taxonomic IDs translation_filename = os.path.abspath(sys.argv[2]) assert translation_filename.endswith(".csv") # set the output filename out_filename = os.path.abspath(sys.argv[3]) assert out_filename.endswith(".csv") # read the input tables using pandas translate_df = pd.read_csv(translation_filename) rafah_df = pd.read_csv(rafah_filename, sep='\t') # we are only interested in the first 3 columns rafah_df = rafah_df.iloc[:, :3] # create a dictionary for efficient matching of NCBI to GTDB translation_dict = {get_ncbi_genus(r["ncbi_taxonomy"]):get_gtdb_upto_genus(r["gtdb_taxonomy"]) for i, r in translate_df.iterrows()} # translate all NCBI genus predictions to GTDB. # We don't manipulate the table while iterating over it because this could lead to problems. translated_hosts = [] for i, row in rafah_df.iterrows(): translated_hosts.append(translation_dict[row["Predicted_Host"]] if row["Predicted_Host"] in translation_dict else "no_translation") # add the translated predictions to the dataframe and save the table. rafah_df["Predicted_Host"] = translated_hosts rafah_df.to_csv(out_filename,index=False) if __name__ == "__main__": main()
sbatch script for host prediction with RaFAH
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=32 #SBATCH --partition=short,standard #SBATCH --mem=50G #SBATCH --time=02:00:00 #SBATCH --job-name=rafah #SBATCH --output=10_rafah/rafah.slurm.%j.out #SBATCH --error=10_rafah/rafah.slurm.%j.err assembly='../1.3_virus_identification/30_filter_contigs/assembly.fasta' contigs='10_rafah/split_contigs' mkdir -p "$contigs" # RaFAH expects each genome in a separate file. Activate our virtual environment # and run a python script to split our filtered assembly into single files source ../py3env/bin/activate # The script requires the assmbly path and a directory for outputting the contigs python ../python_scripts/2.1_split_assembly.py $assembly $contigs # deactivate the python environment, just to be sure not to cause problems with the conda environment RaFAH needs deactivate # activate the conda environment with the dependencies RaFAH requires source /vast/groups/VEO/tools/miniconda3_2024/etc/profile.d/conda.sh && conda activate perl_v5.32.1 # set a variable to call the RaFAH script rafah='/home/groups/VEO/tools/rafah/RaFAH.pl' # rafah parameters (https://gensoft.pasteur.fr/docs/RaFAH/0.3/) # --predict: run the pipeline for predicting hosts # --genomes_dir: the directory with the separate files for each contig # --extension: the extension of the contig files # --file_prefix: can specify an output dir here and "run name" (rafah_1) here perl "$rafah" --predict --genomes_dir $contigs --extension .fasta --file_prefix 10_rafah/rafah_1 # deactivate RaFAH's conda environment conda deactivate # Our python script for translating the Taxonomy needs our python environment again source ../py3env/bin/activate # set the path to the table with the translation between NCBI and GTDB and to RaFAH output translation='10_rafah/ncbi_to_gtdb.csv' rafahtable='10_rafah/rafah_1_Host_Predictions.tsv' # run our script with the appropriate file names as parameters python3 ../python_scripts/2.1_translate_ncbi_to_gtdb.py $rafahtable $translation 10_rafah/rafah_1_Host_Predictions_gtdb.csv deactivate
Host Prediction using Blastn
While RaFAH uses a database of reference bacterial/archaeal genomes to find hosts, these bacteria/archaea may or may not be in your samples. One of the simplest ways to look for potential hosts is to do a quick blastn. Viral genomes often contain fragments of host DNA, for example an auxiliary metabolic gene. Conversely, viral DNA can also be found in host genomes; e.g. prophages, CRISPR spacers, fragments of viral genes, tRNAs etc.
For this task, we assembled metagnome-assembled-genomes (MAGs or bins) of the prokaryotic community from the same three samples given to you. This resulted in 110 MAGs. However, not all of these are complete and many are contaminated. After filtering for a completeness >= 50% and a contamination <= 6%, 19 “good MAGs” remained.
These “good MAGs” were concatenated and are located /work/groups/VEO/shared_data/Viromics2024Workspace/test_run/2.1_host_prediction/20_blastn/good_bins_all.fa. These MAGs will be the “database” against which we align our viral contigs (query sequences)
You also require the GTDB taxonomic classifications for the bins. These are located /work/groups/VEO/shared_data/Viromics2024Workspace/2.3_bacterial_binning/40_gtdbtk/results/gtdbtk.bac120.summary.tsv
Exercise - copy the MAGs and the gtdb bin classification over
Please copy this fasta file into your own directory
# make a new directory for this analysis mkdir ./2.1_host_prediction/20_blastn/ # copy over the good MAGs cp /work/groups/VEO/shared_data/Viromics2024Workspace/test_run/2.1_host_prediction/20_blastn/good_bins_all.fa ./2.1_host_prediction/20_blastn/ # copy over the taxonomic classification for the MAGs cp /work/groups/VEO/shared_data/Viromics2024Workspace/2.3_bacterial_binning/40_gtdbtk/results/gtdbtk.bac120.summary.tsv ./2.1_host_prediction/20_blastn/gtdbtk.bac120.summary.tsv
Next, we will create a custom blast database using our MAGs fasta file and use blastn (nucleotide-nucleotide) to do the alignment
Exercise - makeblastdb and blastn
Create an sbatch script for the makeblastdb and blastn
- makeblastdb is located at
/home/groups/VEO/tools/blast/v2.14.0/bin/makeblastdb- blastn is located at
/home/groups/VEO/tools/blast/v2.14.0/bin/blastn- A conda environment is NOT required for this tool!
The basic usage for the makeblastdb and blastn are the following
NOTE: the database you create in makeblastdb has to be fed into blastn
# make a custom database makeblastdb -in mags_file.fasta -out mags_file.fasta -dbtype nucl # run blastn with the file.fasta database blastn -db mags_file.fasta -query filtered_cross_assembly.fasta -out viral_contigs_vs_bins_blastn.out -num_threads 32 -outfmt 6Resources for blastn can vary! Large databases require a lot of computational power and will take a long time but luckily our task is very small. We recommend the following resources
#SBATCH –cpus-per-task=32
#SBATCH –partition=short,standard
#SBATCH –mem=5G
#SBATCH –time=01:00:00
-outfmt 6 : is an output format that is tabular. Your output contains the following 12 columns in THIS order
query, subject, pid, aln_length, mismatch, gapopen, qstart, qend, sstart, send, evalue, bitscore
query : query id - this is your viral contig
subject : subject id - this is the bin and contig it matches
pid : percent id of the match
aln_length : alignment length
mismatch : number of mismatches
gapopen : number of gaps
qstart, qend : start and end positions of query sequence
sstart, send : start and end positions of subject sequence
evalue : expect value (the lower, the better)
bitscore : a score based on gaps, mismatches, % id and alignment length
More resources for blast output formats here and blast manual
sbatch script for blast tasks
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=32 #SBATCH --partition=short,standard #SBATCH --mem=5G #SBATCH --time=01:00:00 #SBATCH --job-name=blastn #SBATCH --output=./2.1_host_prediction/20_blastn/blastn.slurm.%j.out #SBATCH --error=./2.1_host_prediction/20_blastn/blastn.slurm.%j.err # the blast tools makeblastdb='/home/groups/VEO/tools/blast/v2.14.0/bin/makeblastdb' blastn='/home/groups/VEO/tools/blast/v2.14.0/bin/blastn' # the query (filtered cross assembly) and subject (MAGs fasta) assembly='./1.3_virus_identification/40_results_filter_contigs/assembly.fasta' bins_fasta='./2.1_host_prediction/20_blastn/good_bins_all.fa' $makeblastdb -in $bins_fasta -out $bins_fasta -dbtype nucl $blastn -db $bins_fasta -query $assembly -out ./2.1_host_prediction/20_blastn/viral_contigs_vs_bins_blastn.out -num_threads 32 -outfmt 6
Exercise - analyzing blast results
- How many total hits did you get from blastn?
- How many of these hits would you trust?
- How many unique viral contigs were you able to get host predictions for from blastn?
- Was there cases where 1 viral contig hit multiple MAGs?
a) which interaction would you then trust?
Combining results for blast and RaFAH
Now we can write a python script to combine the results from RaFAH and blastn to compare the host predictions from different method. You might use pandas dataframes and pd.join or pd.merge to write this.
You will need the following 3 files:
- the blast output:
./2.1_host_prediction/20_blastn/viral_contigs_vs_bins_blastn.outfile - the taxonomic classifications for the MAGs:
./2.1_host_prediction/20_blastn/gtdbtk.bac120.summary.tsv - the rafah results with the converted taxonomy:
./2.1_host_prediction/10_rafah/rafah_1_Host_Predictions_gtdb.csv
py script for merging the blastn and rafah results
import pandas as pd import sys # read in the files blast = sys.argv[1] taxa = sys.argv[2] rafah = sys.argv[3] out = sys.argv[4] df_rafah = pd.read_csv(rafah, header=0) print(df_rafah) df_bins_gtdb = pd.read_csv(taxa, sep='\t' ,header=0) print(df_bins_gtdb) df_blast = pd.read_csv(blast, sep='\t', header=None, names=['query', 'subject', 'pid', 'aln_length', 'mismatch', 'gapopen', 'qstart', 'qend', 'sstart', 'send', 'evalue', 'bitscore']) print(df_blast.head(n=10)) # add MAG taxonomy to the blast results df_blast['bin'] = df_blast['subject'].str.split('.fa').str[0] print(df_blast.head(n=10)) df_blast_gtdb_merged = df_blast.merge(df_bins_gtdb[['user_genome','classification']], how='left', left_on='bin', right_on='user_genome') print(df_blast_gtdb_merged.head(n=10)) # merge blast results with rafah df_blast_gtdb_rafah_merged = df_blast_gtdb_merged.merge(df_rafah,how='left',left_on='query',right_on='Sequence',suffixes=(None,'_rafah')) df_blast_gtdb_rafah_merged # select relevant columns df_blast_gtdb_rafah_merged=df_blast_gtdb_rafah_merged[['query', 'subject', 'pid', 'aln_length', 'mismatch', 'gapopen', 'qstart', 'qend', 'sstart', 'send', 'evalue', 'bitscore', 'bin', 'classification','Predicted_Host', 'Winner_Score']] # rename the columns to meaningful headers df_blast_gtdb_rafah_merged = df_blast_gtdb_rafah_merged.rename(columns = {'query':'viral_contig', 'subject':'host_bin_contig','bin':'host_bin','classification':'blast_predicted_host','Predicted_Host':'rafah_predicted_host', 'Winner_Score':'rafah_score'}) print(df_blast_gtdb_rafah_merged) # write out to a csv df_blast_gtdb_rafah_merged.to_csv(out,index=False)
sbatch script for blast tasks
#!/bin/bash #SBATCH --tasks=1 #SBATCH --cpus-per-task=10 #SBATCH --partition=short #SBATCH --mem=5G #SBATCH --time=01:00:00 #SBATCH --job-name=combine #SBATCH --output=./2.1_host_prediction/30_combined_results/combine.slurm.%j.out #SBATCH --error=./2.1_host_prediction/30_combined_results/combine.slurm.%j.err # Our python script for combining blastn and rafah needs our python environment again source ./py3env/bin/activate # file paths blast='./2.1_host_prediction/20_blastn/viral_contigs_vs_bins_blastn.out' gtdb='./2.1_host_prediction/20_blastn/gtdbtk.bac120.summary.tsv' rafah='./2.1_host_prediction/10_rafah/rafah_1_Host_Predictions_gtdb.csv' output='./2.1_host_prediction/30_combined_results/combined_blast_rafah_host_predictions.csv' python3 ./python_scripts/host_prediction/30_combine_host_prediction.py $blast $gtdb $rafah $output
Exercise - comparing RaFAH and blast results
- For how many host predictions, do RaFAH and blastn agree and upto which taxonomic level?
- Are you able identify CRISPRs or integrated phage genomes?
a) Explain your decision
b) How might you confirm your CRISPR/prophage identification?- Pick one example where you would trust RaFAH predictions more and another where you would trust blast predictions more and explain why.
Key Points
RaFAH uses a random forest model to predict hosts to the genus level for phages
RaFAH returns a probability for each host genus it can predict.
Blastn between the viral and prokaryotic fractions can be used as a quick method for host prediction
Machine learning and classical host prediction methods have a trade-off between recall and sensitivity
Statistics lecture
Overview
Teaching: 60 min
Exercises: minObjectives
Attend the lecture “Introduction to Statistics”
Listen to lecture by Bia (pay attention!!!)
Slides of the lecture can be found here.
If you want to deepen your knowledge, you could follow the practical exercise later (manual t-test)
Key Points
Designing a research project
Overview
Teaching: min
Exercises: 420 minObjectives
Develop a conceptual pipeline of analysis
Define a hypothesis based on your research question
Choose one or more papers for inspiration
Create a flow diagram (workflow or pipeline)
Plan to end your project with an ecological hypothesis
To close off this course, we would like to give you the opportunity to design your own research project. Viromics is a new field, the virosphere is huge, and there is a LOT of data, so there are more unanswered than answered questions. We thought of three projects, all inspired by the experiments done in the wet lab in the module “Viromics - Virome isolation and sequencing”:
How does the addition of the target phage and host impact:
- the outcome of the community at the last time point?
- the host range of the target phage?
- the time dynamics of the target phage/host?
Each student should choose one of the topics above and work on their project individually. Organize yourselves so that you do not choose the same topic. Take the topic above as inspiration and refine the ideas by searching the literature and discussing with your colleagues and the teachers. It is important to have a clear hypothesis at the start of your project.
How to make a clear, data-driven hypothesis? Start with a specific question, which is neither too broad, now too narrow. For example: how does adding a target phage and host affect the virome community? This is a singular question that can be answered by comparing two datasets - one with the target phage/host and another without the target phage/host. It is crucial to manage your time in the set up and execution of your research project. After creating the hypothesis, you should also do some literature search. Then, make a workflow describing the methods (programs, databases), inputs, outputs and required statistics. An example of a workflow can be seen here. Always discuss your ideas with one of the teachers.
{kind=link}
Documentation
Do not forget to document the development of the project in your lab book. Write down your hypothesis, any relevant papers, methods, databases, etc. Below are points that should be included in your documentation:
- A brief background on the topic
- A workflow for the steps you plan to take
- What will be the inputs and outputs?
- Which programs do you plan to use?
Presentation
The points below are what we expect to see in your final presentation:
- Background on the topic that lead to the research question (1-2 slides)
- Hypothesis and brief overview of the literature
- Workflow figure to describe the analysis
- A rationale for why you choose those methods
- What are the inputs?
- What do you expect to get as output?
- Which result would confirm and which result would refute the initial hypothesis?
- Things you found particularly interesting
Exercise
- Create a clear, data-driven hypothesis, and discuss it with teachers and fellow students. Often your initial idea can be further refined based on discussions with others.
- Make sure you check the literature Find at least one paper that is closely related to your project, and use it/them to refine your question.
- Methods: Make a plan for tackling your question(s) in the form of a workflow. Think about data sources, bioinformatic methods, possible outcomes, expectations, backup/follow-up plans, hypotheses, and possible interpretation.
Key Points
Working on project
Overview
Teaching: min
Exercises: 180 minObjectives
Work on your own project
Clarify unclear points with your teachers
This morning please continue working on your research project design. Additionally, we have open hours with the teachers. Discuss the project and/or clarify any open issues with them.
Key Points
Working on project
Overview
Teaching: min
Exercises: 300 minObjectives
Work on your own project
Clarify unclear points with your teachers
This afternoon please continue working on your project. Additionally, we have open hours with the teachers. Discuss the project and/or clarify any open issues with them.
Key Points
Working on project
Overview
Teaching: min
Exercises: 180 minObjectives
Work on your own project
Clarify unclear points with your teachers
This morning please continue working on your research project design. Additionally, we have open hours with the teachers. Discuss the project and/or clarify any open issues with them.
Key Points
Prepare Presentation
Overview
Teaching: min
Exercises: 300 minObjectives
Prepare your final presentation
Take the time today to prepare your final presentation.
Key Points
Presentation
Overview
Teaching: min
Exercises: 180 minObjectives
Present your progress
Get feedback
Present your progress and get feedback from the teachers and your colleagues.
Key Points
Send Documentation
Overview
Teaching: min
Exercises: 180 minObjectives
Clean up documentation and scripts
Send all required documentation to your teachers
In your final hours on the module, clean up your lab book, scripts and any additional documentation and send them to your teachers. We hope you learned interesting things during the module and wish you all the best!
Key Points